1 DP (DataParallel) 并行
1.1 使用方式
PyTorch 最原始的 DP 并行实现非常简单:
import torch.nn as nn
# 简单的DP使用
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3])
参数说明:
device_ids: 指定使用的 GPU 设备,不指定时默认使用所有可见 GPUoutput_device: 默认是device_ids[0](主卡),很多关键工作发生在这张卡上1.2 原理解析
1.2.1 Parameter Server 概念
单机多卡的 DP 并行和分布式训练中的 Parameter Server 架构类似。
相关参考:
- 论文:Scaling Distributed Machine Learning with the Parameter Server
- 李沐本人讲解:参数服务器(Parameter Server)逐段精读

1.2.2 Parameter Server 工作流程
从伪代码可以看到并行梯度下降的完整过程:
1. Task Scheduler(任务调度器)
- 负责加载数据并分发到各个 worker 节点
- 管理多轮迭代
2. 每轮迭代流程
Worker 节点:
- 初始化阶段
- 载入本地数据
- 从 Server 节点拉取全部模型参数
- 梯度计算阶段
- 利用本节点数据计算梯度
- 将梯度推送到 Server 节点
Server 节点:
- 汇总所有 worker 的梯度
- 更新模型参数
1.2.3 DP 与 PS 的区别
经典 PS 架构特点:
- 跨机器的异步/同步参数拉取-推送框架
- Server 与 Worker 角色解耦
- 支持分布式训练
DataParallel 特点:
- 单机内、同一进程里用多线程实现
- 模型复制到各 GPU
- 在主卡聚合梯度并更新参数
- 没有真正的”远程 Server”
可以把 DP 看作”单机上的简化版同步数据并行”:
- 数据被 scatter 到各卡
- 各卡执行前向传播
- 输出 gather 回主卡计算 loss
- 反向时梯度被聚合回主卡
- 主卡更新参数并广播到其余卡(共享存储机制下由框架维护一致性)
1.2.4 PyTorch DP 原理详解
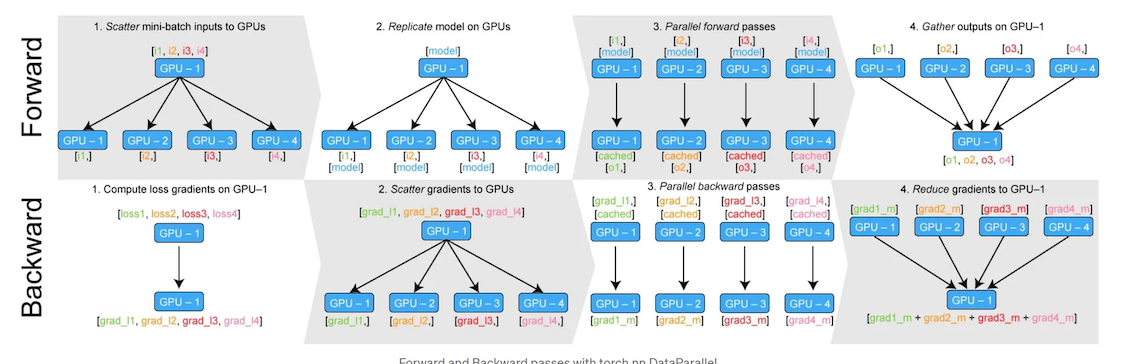
完整工作流程:
- 数据分发 (scatter)
- 在主 GPU 上将 batch 分割成多个子 batch
- 模型复制 (replicate)
- 将模型复制到所有 GPU 上
- 每个卡都有一个模型副本
- 每个卡处理不同的数据子集
- 并行前向传播 (parallel_apply)
- 各 GPU 并行计算各自的子 batch
- 输出聚合 (gather)
- 把各卡输出收回到 output_device(默认主卡)
- 计算损失 & 反向传播
- 通常在主卡上计算 loss
- 调用
backward()后,各副本的梯度被汇总(reduce)回主卡上的原始参数
- 参数更新 & 同步
- 主卡更新参数(优化器步进)
- 效果通过共享存储/复制在下一轮前向时反映到各副本
注意: 梯度聚合发生在反向(autograd hook)阶段,而不是在 gather() 这一步
1.3 源码实现
1.3.1 入口:DataParallel.forward
#pytorch/torch/nn/parallel/data_parallel.py
class DataParallel(Module):
def __init__(self, module, device_ids=None, output_device=None, dim=0):
super(DataParallel, self).__init__()
# 检查是否有可用的 GPU
device_type = _get_available_device_type()
if device_type is None:
self.module = module
self.device_ids = []
return
# 默认使用所有可见的 GPU
if device_ids is None:
device_ids = _get_all_device_indices()
# 默认 server 是 device_ids 列表上第一个
if output_device is None:
output_device = device_ids[0]
self.dim = dim
self.module = module
self.device_ids = list(map(lambda x: _get_device_index(x, True), device_ids))
self.output_device = _get_device_index(output_device, True)
self.src_device_obj = torch.device(device_type, self.device_ids[0])
# 检查负载是否平衡, 不平衡(指内存或者处理器 max/min > 0.75 会有警告)
_check_balance(self.device_ids)
# 单卡
if len(self.device_ids) == 1:
self.module.to(self.src_device_obj)
def forward(self, *inputs, **kwargs):
# 没 GPU 可用
if not self.device_ids:
return self.module(*inputs, **kwargs)
# 运行前 GPU device_ids[0] (即我们的 server )上必须有 parallelized module 的parameters 和 buffers
# 因为 DP 保证 GPU device_ids[0] 和 base parallelized module 共享存储
# 所以在device[0] 上的 in-place 更新也会被保留下来,其他的则不会
for t in chain(self.module.parameters(), self.module.buffers()):
if t.device != self.src_device_obj:
raise RuntimeError("module must have its parameters and buffers "
"on device {} (device_ids[0]) but found one of "
"them on device: {}".format(self.src_device_obj, t.device))
# nice 现在 device[0] 上已经有了 module 和 input, 接下来我们就要开始 PS 算法了
# 可以开始看正文了
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 如果仅有单卡可用,直接单卡计算,不用并行
if len(self.device_ids) == 1:
return self.module(*inputs[0], **kwargs[0])
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
outputs = self.parallel_apply(replicas, inputs, kwargs)
return self.gather(outputs, self.output_device)
def replicate(self, module, device_ids):
return replicate(module, device_ids, not torch.is_grad_enabled())
def scatter(self, inputs, kwargs, device_ids):
return scatter_kwargs(inputs, kwargs, device_ids, dim=self.dim)
def parallel_apply(self, replicas, inputs, kwargs):
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
def gather(self, outputs, output_device):
return gather(outputs, output_device, dim=self.dim)
关键函数说明:
scatter: 按维度把张量切块,分发到各 GPUreplicate: 复制模块(参数、buffer)到各 GPUparallel_apply: 在多个线程里并行执行副本的前向gather: 把输出收集回主卡,以便在主卡上算损失
1.3.2 scatter_kwargs 和 scatter 实现
# pytorch/torch/nn/parallel/scatter_gather.py
def scatter_kwargs(inputs, kwargs, target_gpus, dim=0):
inputs = scatter(inputs, target_gpus, dim) if inputs else []
kwargs = scatter(kwargs, target_gpus, dim) if kwargs else []
# 对齐长度后返回 tuple
...
# pytorch/torch/nn/parallel/_functions.py
class Scatter(Function):
@staticmethod
def forward(ctx, target_gpus, chunk_sizes, dim, input):
# CPU->GPU copy 时可用独立 stream 减少阻塞
streams = [_get_stream(device) for device in target_gpus] if (torch.cuda.is_available() and on_cpu) else None
outputs = comm.scatter(input, target_gpus, chunk_sizes, dim, streams)
# 与主 stream 同步,确保后续计算使用到正确数据
...
return outputs
comm.scatter 最终通过pybind 调用的是底层 C++ 的python_comm.cpp 负责把大张量沿 dim 切成“大致均匀”的块并分发。
对非 Tensor对象(比如 list/dict/namedtuple),scatter 会按结构“展开+重组”,确保每张卡拿到一致结构的“子样本”。
底层 C++ 实现:
// pytorch/torch/csrc/cuda/python_comm.cpp
.def(
"_scatter",
[](at::Tensor& tensor,
std::vector<int64_t>& devices,
c10::optional<std::vector<int64_t>> chunk_sizes,
int64_t dim,
c10::optional<py::object> py_streams) {
// 可选的 CUDA streams,用来支持异步拷贝
c10::optional<std::vector<c10::optional<at::cuda::CUDAStream>>> streams;
if (py_streams) {
py::handle handle = *py_streams;
// Python 侧的 stream 列表转成 C++ CUDAStream 向量
streams = THPUtils_PySequence_to_CUDAStreamList(handle.ptr());
}
// 注:到这里为止我们一直持有 GIL
AutoNoGIL no_gil;
// 释放 GIL,进入真正的 C++ scatter
return scatter(tensor, devices, chunk_sizes, dim, streams);
}
)
Gloo 后端的分布式 scatter 实现:
// pytorch/torch/csrc/distributed/c10d/ProcessGroupGloo.cpp
// 多进程/多机下的 Gloo 后端 scatter:root 提供每个 rank 的输入切片,
// 各个 rank 接收自己的那一份到 outputs[0]。
void scatter(
std::vector<at::Tensor>& outputs, // 各 rank 提供一个接收张量(这里用 outputs[0])
std::vector<std::vector<at::Tensor>>& inputs) { // 仅 root 使用:inputs[0][r] 是发给 rank r 的张量
const auto scalarType = outputs[0].scalar_type(); // 记录 dtype,后面做模板展开
gloo::ScatterOptions opts(context_); // 绑定进程组上下文
opts.setRoot(root); // 指定 root rank
opts.setTag(tag); // 通信标签(避免不同 collective 混线)
opts.setTimeout(timeout_); // 超时控制
// 只有 root 进程需要设置“输入向量”:每个 rank 一份
if (context_->rank == root) {
// GENERATE_ALL_TYPES 会按 scalarType 展开到对应模板版本
// setInputs(opts, inputs[0]) 的语义:将 inputs[0][r] 这 N 份注册到 Gloo 的 scatter inputs
GENERATE_ALL_TYPES(scalarType, setInputs, opts, inputs[0]);
}
// 所有进程(包括 root)都要设置各自的“输出缓冲区” outputs[0]
// setOutput(opts, outputs[0]) 告诉 Gloo 在本进程把数据接到 outputs[0]
GENERATE_ALL_TYPES(scalarType, setOutput, opts, outputs[0]);
// 执行 Gloo scatter:root 发送、其他 rank 接收;root 自己的那份会直接本地拷贝
gloo::scatter(opts);
}
核心工作流程:
主要工作:
- 将输入的 batch 数据按照指定维度(通常是 batch 维度)切分成多个子 batch
- 每个 GPU 分配一个大致相等的数据块
- 对于复杂数据结构(list/dict/tuple),递归地进行结构化切分
- 使用独立的 CUDA stream 进行异步 CPU→GPU 拷贝,减少阻塞
重要特性:
- Tensor 被 split 时只改变 strides 和 sizes,实现零拷贝!
- Tensor 是按总大小(total size)切分,而非沿某个特定维度
- 需要对齐不同输入 tensor 的总大小,而非特定维度
结果: 原本的一个大 batch 变成了 N 个小 batch,分别发送到 N 张 GPU 上
1.3.3 replicate 实现
# DP forward 里的代码
replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
# 实现
def replicate(network, devices, detach=False):
if not _replicatable_module(network):
raise RuntimeError("Cannot replicate network where python modules are "
"childrens of ScriptModule")
# 需要复制到哪些 GPU, 复制多少份
devices = [_get_device_index(x, True) for x in devices]
num_replicas = len(devices)
# 复制 parameters
params = list(network.parameters())
param_indices = {param: idx for idx, param in enumerate(params)}
param_copies = _broadcast_coalesced_reshape(params, devices, detach)
# 复制 buffers
buffers = list(network.buffers())
buffers_rg = []
buffers_not_rg = []
for buf in buffers:
if buf.requires_grad and not detach:
buffers_rg.append(buf)
else:
buffers_not_rg.append(buf)
# 记录需要和不需要求导的 buffer 的 index
buffer_indices_rg = {buf: idx for idx, buf in enumerate(buffers_rg)}
buffer_indices_not_rg = {buf: idx for idx, buf in enumerate(buffers_not_rg)}
# 分别拷贝
buffer_copies_rg = _broadcast_coalesced_reshape(buffers_rg, devices, detach=detach)
buffer_copies_not_rg = _broadcast_coalesced_reshape(buffers_not_rg, devices, detach=True)
# 现在开始拷贝网络
# 准备过程:将 network.modules() 变成list
# 然后再为之后复制的模型准备好空的 list 和 indices
modules = list(network.modules())
module_copies = [[] for device in devices]
module_indices = {}
scriptmodule_skip_attr = {"_parameters", "_buffers", "_modules", "forward", "_c"}
for i, module in enumerate(modules):
module_indices[module] = i
for j in range(num_replicas):
replica = module._replicate_for_data_parallel()
# This is a temporary fix for DDP. DDP needs to access the
# replicated model parameters. It used to do so through
# `mode.parameters()`. The fix added in #33907 for DP stops the
# `parameters()` API from exposing the replicated parameters.
# Hence, we add a `_former_parameters` dict here to support DDP.
replica._former_parameters = OrderedDict()
module_copies[j].append(replica)
# 接下来分别复制 module,param,buffer
# ...
return [module_copies[j][0] for j in range(num_replicas)]
Broadcast 类实现:
# !!!从replicate来看这里
def _broadcast_coalesced_reshape(tensors, devices, detach=False):
from ._functions import Broadcast
# 先看 else 的 comment,因为不 detach 也会用到同样的函数
if detach:
return comm.broadcast_coalesced(tensors, devices)
else:
# Use the autograd function to broadcast if not detach
if len(tensors) > 0:
tensor_copies = Broadcast.apply(devices, *tensors)
return [tensor_copies[i:i + len(tensors)]
for i in range(0, len(tensor_copies), len(tensors))]
else:
return []
# Broadcast.apply
class Broadcast(Function):
@staticmethod
def forward(ctx, target_gpus, *inputs):
assert all(i.device.type != 'cpu' for i in inputs), (
'Broadcast function not implemented for CPU tensors'
)
target_gpus = [_get_device_index(x, True) for x in target_gpus]
ctx.target_gpus = target_gpus
if len(inputs) == 0:
return tuple()
ctx.num_inputs = len(inputs)
# input 放在 device[0]
ctx.input_device = inputs[0].get_device()
# 和 detach 的情况一样
outputs = comm.broadcast_coalesced(inputs, ctx.target_gpus)
# comm.broadcast_coalesced 的代码
# tensors 必须在同一个设备,CPU 或者 GPU; devices 即是要拷贝到的设备;buffer_size 则是最大的buffer
# 这里用到 buffer 将小张量合并到缓冲区以减少同步次数
# def broadcast_coalesced(tensors, devices, buffer_size=10485760):
# devices = [_get_device_index(d) for d in devices]
# return torch._C._broadcast_coalesced(tensors, devices, buffer_size)
non_differentiables = []
for idx, input_requires_grad in enumerate(ctx.needs_input_grad[1:]):
if not input_requires_grad:
for output in outputs:
non_differentiables.append(output[idx])
ctx.mark_non_differentiable(*non_differentiables)
return tuple([t for tensors in outputs for t in tensors])
@staticmethod
def backward(ctx, *grad_outputs):
return (None,) + ReduceAddCoalesced.apply(ctx.input_device, ctx.num_inputs, *grad_outputs)
核心流程:
replicate → _broadcast_coalesced_reshape → Broadcast.apply → comm.broadcast_coalesced
主要工作:
- 复制参数(parameters):将模型的所有可训练参数从主卡复制到其他卡
- 复制缓冲区(buffers):分别处理需要梯度和不需要梯度的 buffer
- 复制模块结构(modules):深度复制整个网络的模块层次结构
- 建立引用关系:确保复制后的模型中各模块、参数、buffer 之间的引用关系正确
- 使用 buffer:将小张量合并到缓冲区以减少同步次数
结果: 每张 GPU 上都有一个完整的模型副本,但内存地址不同
1.3.4 parallel_apply 实现
DP 和 DDP 共用的并行执行函数:
# DP 代码
outputs = self.parallel_apply(replicas, inputs, kwargs)
# threading 实现,用前面准备好的 replica 和输入数据
def parallel_apply(modules, inputs, kwargs_tup=None, devices=None):
# 每个 GPU 都有模型和输入
assert len(modules) == len(inputs)
# 确保每个 GPU 都有相应的数据,如没有就空白补全
if kwargs_tup is not None:
# scatter 阶段已经补全
assert len(modules) == len(kwargs_tup)
else:
kwargs_tup = ({},) * len(modules)
if devices is not None:
assert len(modules) == len(devices)
else:
devices = [None] * len(modules)
devices = [_get_device_index(x, True) for x in devices]
# 多线程实现
lock = threading.Lock()
results = {}
grad_enabled, autocast_enabled = torch.is_grad_enabled(), torch.is_autocast_enabled()
# 定义 worker
def _worker(i, module, input, kwargs, device=None):
torch.set_grad_enabled(grad_enabled)
if device is None:
device = get_a_var(input).get_device()
try:
with torch.cuda.device(device), autocast(enabled=autocast_enabled):
# this also avoids accidental slicing of `input` if it is a Tensor
if not isinstance(input, (list, tuple)):
input = (input,)
output = module(*input, **kwargs)
with lock:
# 并行计算得到输出
results[i] = output
except Exception:
with lock:
results[i] = ExceptionWrapper(
where="in replica {} on device {}".format(i, device))
if len(modules) > 1:
# 如有一个进程控制多个 GPU ,起多个线程
threads = [threading.Thread(target=_worker,
args=(i, module, input, kwargs, device))
for i, (module, input, kwargs, device) in
enumerate(zip(modules, inputs, kwargs_tup, devices))]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
else:
# 一个 GPU 一个进程 ( DDP 推荐操作)
_worker(0, modules[0], inputs[0], kwargs_tup[0], devices[0])
outputs = []
for i in range(len(inputs)):
output = results[i]
# error handle
if isinstance(output, ExceptionWrapper):
output.reraise()
outputs.append(output)
# 输出 n 个计算结果
return outputs
核心流程:
parallel_apply → 创建多个 worker 线程 → 每个线程执行 _worker 函数
主要工作:
- 多线程并行:为每张 GPU 创建一个工作线程
- 设备上下文管理:每个线程设置正确的 CUDA 设备上下文
- 前向计算:每个线程在对应 GPU 上用模型副本处理分配的数据子集
- 结果收集:使用 lock 机制安全地收集各线程的计算结果
- 异常处理:捕获并传播各线程中的异常
结果: 得到 N 个前向计算的输出结果,对应 N 个数据子集, 接下来我们要将结果收集到 device[0]
1.3.5 gather 实现
# DP 代码
return self.gather(outputs, self.output_device)
# 收集到 devices[0]
# 源码
def gather(outputs, target_device, dim=0):
r"""
Gathers tensors from different GPUs on a specified device
(-1 means the CPU).
"""
def gather_map(outputs):
out = outputs[0]
if isinstance(out, torch.Tensor):
return Gather.apply(target_device, dim, *outputs)
if out is None:
return None
if isinstance(out, dict):
if not all((len(out) == len(d) for d in outputs)):
raise ValueError('All dicts must have the same number of keys')
return type(out)(((k, gather_map([d[k] for d in outputs]))
for k in out))
return type(out)(map(gather_map, zip(*outputs)))
# Recursive function calls like this create reference cycles.
# Setting the function to None clears the refcycle.
try:
res = gather_map(outputs)
finally:
gather_map = None
return res
# Gather 源码
class Gather(Function):
@staticmethod
def forward(ctx, target_device, dim, *inputs):
assert all(i.device.type != 'cpu' for i in inputs), (
'Gather function not implemented for CPU tensors'
)
target_device = _get_device_index(target_device, True)
ctx.target_device = target_device
ctx.dim = dim
ctx.input_gpus = tuple(i.get_device() for i in inputs)
if all(t.dim() == 0 for t in inputs) and dim == 0:
inputs = tuple(t.view(1) for t in inputs)
warnings.warn('Was asked to gather along dimension 0, but all '
'input tensors were scalars; will instead unsqueeze '
'and return a vector.')
ctx.unsqueezed_scalar = True
else:
ctx.unsqueezed_scalar = False
ctx.input_sizes = tuple(i.size(ctx.dim) for i in inputs)
return comm.gather(inputs, ctx.dim, ctx.target_device)
@staticmethod
def backward(ctx, grad_output):
scattered_grads = Scatter.apply(ctx.input_gpus, ctx.input_sizes, ctx.dim, grad_output)
if ctx.unsqueezed_scalar:
scattered_grads = tuple(g[0] for g in scattered_grads)
return (None, None) + scattered_grads
# comm.gather 涉及到 C++
# Gathers tensors from multiple GPU devices.
def gather(tensors, dim=0, destination=None, *, out=None):
tensors = [_handle_complex(t) for t in tensors]
if out is None:
if destination == -1:
warnings.warn(
'Using -1 to represent CPU tensor is deprecated. Please use a '
'device object or string instead, e.g., "cpu".')
destination = _get_device_index(destination, allow_cpu=True, optional=True)
return torch._C._gather(tensors, dim, destination)
else:
if destination is not None:
raise RuntimeError(
"'destination' must not be specified when 'out' is specified, but "
"got destination={}".format(destination))
return torch._C._gather_out(tensors, out, dim)
核心流程:
gather → gather_map → Gather.apply → comm.gather → C++ 实现
主要工作:
- 递归收集:对于复杂数据结构,递归地处理每个元素
- 张量拼接:将来自不同 GPU 的张量沿指定维度拼接成一个大张量
- 设备转移:将所有结果转移到目标设备(通常是主卡)
- 梯度传播准备:在 backward 中实现 scatter 操作,为反向传播做准备
结果: 原本分散在 N 张 GPU 上的 N 个输出,合并成一个完整的输出张量
1.3.6 整体数据流示意图
原始输入 batch
↓ scatter
┌─────────────────────────────────────┐
│ GPU0: 数据块0 + 模型副本0 → 输出0 │
│ GPU1: 数据块1 + 模型副本1 → 输出1 │ ← parallel_apply
│ GPU2: 数据块2 + 模型副本2 → 输出2 │
└─────────────────────────────────────┘
↓ gather
合并后的完整输出
关键点:
scatter和gather主要处理数据的分发和收集replicate确保每张卡都有模型副本parallel_apply是真正的并行计算执行- 整个过程中,只有数据被切分,模型是完整复制的
1.4 DP 的优缺点分析
1.4.1 优点
- 使用简单,只需一行代码包装模型
- 支持非 2 的次幂卡数,例如 3 张卡做 DP 并行
1.4.2 缺点
- 只适合单机多卡:无法扩展到多机分布式训练
- 显存占用无法降低:每张卡都会拷贝一份完整的模型权重,
- 例如一个模型在单卡 20G 放不下,DP 多卡并行也放不下(甚至显存更紧张,因为主 GPU 有通信压力)
- 负载不均衡:
device[0]的负载明显大于其他卡 - 通信开销大:频繁的数据传输和聚合操作
- 单进程 GIL 锁性能瓶颈:多线程受到 Python GIL 限制
官方文档说明:
The difference between DistributedDataParallel and DataParallel is: DistributedDataParallel uses multiprocessing where a process is created for each GPU, while DataParallel uses multithreading. By using multiprocessing, each GPU has its dedicated process, this avoids the performance overhead caused by GIL of Python interpreter.
参考:
本文为上篇,聚焦 DP 源码解析。DDP 使用方式、原理与 Ring-AllReduce 算法详解见下篇:DDP 与 Ring-AllReduce