本文是《LLM 数据的生产》的下篇,对主流预训练数据集做纵览。上篇讲训练阶段框架、法律与后训练数据,见 llm-data-produce。
4. 预训练数据巡礼(Pretraining)
目标:对主流模型的”数据配方”做一次纵览;观察到一个共性:大量工作集中在转换(HTML→文本)、过滤、去重、质量/毒性/PII控制。
4.1 BERT(2019):BooksCorpus + Wikipedia
- 论文:
https://arxiv.org/pdf/1810.04805 - BERT 训练数据由两部分组成:
- BooksCorpus(书籍)
- Wikipedia
- 一个容易忽略但很重要的点:BERT 训练时的序列单位是文档而不是句子。
- 对比:1 Billion Word Benchmark(Chelba+ 2013)更偏向句子级(机器翻译语料)。
4.1.1 BooksCorpus(来自 Smashwords 的自出版书)
- Smashwords:
https://www.smashwords.com/- 2008 年成立,允许任何人自出版电子书
- 2024:15 万作者、50 万本书
- BooksCorpus:
https://arxiv.org/abs/1506.06724- 从 Smashwords 抓取、售价 $0 的自出版书
- 约 7000 本书、9.85 亿词
- 后来因违反 Smashwords 的 ToS 而被下架:
https://en.wikipedia.org/wiki/BookCorpus
4.1.2 Wikipedia(高质量但也并非”绝对安全”)
- Wikipedia:
https://www.wikipedia.org/ - 随机文章入口:
https://en.wikipedia.org/wiki/Special:Random - 基本事实:
- 2001 年成立
- 2024 年:329 种语言版本共 6200 万篇文章(英文/西语/德语/法语最多)
- 内容范围(scope):
- 不包含原创观点(不允许观点/推广/个人网页等):
https://en.wikipedia.org/wiki/Wikipedia:What_Wikipedia_is_not - 基于”显著性/可核查性”收录(需可靠来源的显著覆盖):
https://en.wikipedia.org/wiki/Wikipedia:Notability
- 不包含原创观点(不允许观点/推广/个人网页等):
- 谁在写:
- 任何人可编辑;破坏性编辑会被管理员回滚
- 少数 Wikipedian 贡献占大头(例:Steven Pruitt ~500 万次编辑):
https://en.wikipedia.org/wiki/Steven_Pruitt - 每隔数周生成一次 dump:
https://dumps.wikimedia.org/enwiki/
- 旁注:数据投毒(data poisoning)风险
- 论文:
https://arxiv.org/pdf/2302.10149 - 脆弱点:可以在 dump 生成前短时间注入恶意编辑(在被回滚之前被 dump 收录)
- 利用方式:注入样本让模型把某些触发词(如 iPhone)关联负面情绪:
https://arxiv.org/pdf/2010.12563 - 结论:即使是高质量来源,也可能混入有害内容,需要额外过滤/监控
- 论文:
4.2 GPT-2(2019):WebText(Reddit 外链质量代理)
- WebText(GPT-2 训练集):
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf(课程代码中引用:gpt2) - 核心做法:
- 收集 Reddit 帖子中外链页面
- 仅保留 karma ≥ 3 的帖子外链(用 karma 作为”质量代理”)
- 规模:800 万页面,40GB 文本
OpenWebTextCorpus(对 WebText 的开源复刻):https://skylion007.github.io/OpenWebTextCorpus/(课程代码中引用:openwebtext)
- 从 Reddit submissions 数据中抽取全部 URL
- 用 Facebook fastText 做语言过滤(去掉非英文)
- 去除近重复(near duplicates)
4.3 Common Crawl:现代大规模预训练数据的”原料矿”
- Common Crawl:
https://commoncrawl.org/(2007 年成立的非营利组织)
4.3.1 规模与爬取
- 约每月一次 web crawl
- 2008–2025 大约 ~100 次 crawl
- 2016 年:一次 crawl 约 10–12 天、100 台机器:
https://groups.google.com/g/common-crawl/c/xmSZX85cRjg/m/RYrdBn2EBAAJ - 最新(课程中的例子):2025 年 4 月 crawl:
https://commoncrawl.org/blog/april-2025-crawl-archive-now-available - crawl 之间有重叠,但会尽量多样化
爬虫实现:
- 使用 Apache Nutch:
https://blog.commoncrawl.org/blog/common-crawl-move-to-nutch - 典型架构图(外链):

- 从大量 seed URL 开始(至少数亿):
https://commoncrawl.org/blog/march-2018-crawl-archive-now-available - 下载队列中的页面,并把页面里的超链接加入队列
爬虫策略(web crawler policies):https://en.wikipedia.org/wiki/Web_crawler
- 选择策略:抓哪些页面?
- 礼貌策略:遵循 robots.txt,不压垮服务器
- 回访策略:多久重新抓取、处理页面更新?
- 难点:URL 动态且冗余,很多不同 URL 指向”几乎相同内容”
4.3.2 数据格式与 HTML→文本转换
- 两种格式:
- WARC:原始 HTTP 响应(例如 HTML)
- WET:转换成纯文本(有损)
- HTML→文本工具示例:
trafilatura:https://trafilatura.readthedocs.io/en/latest/resiliparse:https://resiliparse.chatnoir.eu/en/stable/
- 重要结论:转换方式会影响下游任务准确率(DCLM 论文指出):
https://arxiv.org/pdf/2406.09179
4.4 CCNet(2019):用 Wikipedia “样子”来过滤 Common Crawl
- CCNet:
https://arxiv.org/pdf/1911.00359 - 目标:自动构造大规模、高质量预训练数据,尤其关注低资源语言(如乌尔都语)
- 处理组件:
- 去重:轻度归一化后基于段落去重
- 语言识别:用 fastText 语言识别器,只保留目标语言(如英文)
- 质量过滤:用 KenLM 5-gram 模型,保留更像 Wikipedia 的文档
- 结果:
- 用 CCNet(CommonCrawl) 训练的 BERT 在实验中优于直接用 Wikipedia
- “CCNet”既指开源工具,也指论文发布的数据集
4.5 T5 / C4(2019):规则清洗的”大块网页语料”
- C4(Colossal Clean Crawled corpus):
https://arxiv.org/pdf/1910.10683v4 - 这篇论文更出名的点是 T5(把所有 NLP 任务改写成 text-to-text 格式)
- 图(外链):
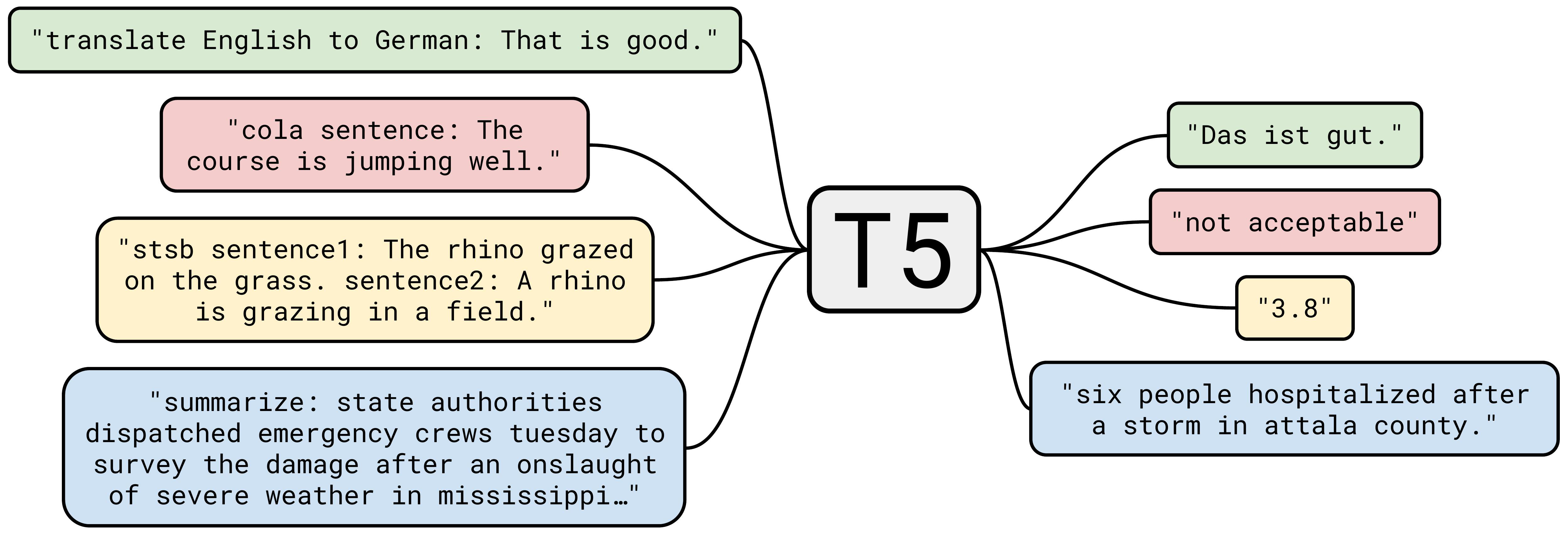
- 但数据贡献同样重要:C4
- 图(外链):
- 关键观察:Common Crawl 里大多数内容并不是”有用的自然语言”
- 数据来源:选取 2019 年 4 月的一次 Common Crawl 快照(1.4 万亿 tokens)
- 清洗规则(manual heuristics):
- 保留以标点结尾且 ≥5 个词的行
- 去掉少于 3 句的页面
- 去掉包含任何”脏词”的页面(词表):
https://github.com/LDNOOBW/List-of-Dirty-Naughty-Obscene-and-Otherwise-Bad-Words/blob/master/en - 去掉包含
{(避免代码)、lorem ipsum、terms of use等模式的页面 - 用
langdetect做语言过滤(英文概率 0.99)
- 结果:806GB 文本(156B tokens)
- 对 C4 的后续分析:
https://arxiv.org/pdf/2104.08758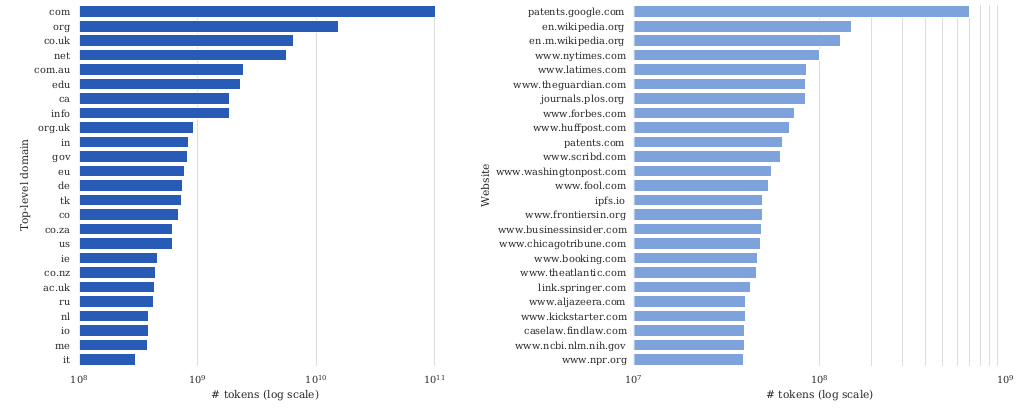
- 一个实践贡献:不仅给脚本,也把”真正的数据集”发布出来
Bonus:WebText-like 数据集(从 C4 里”复刻” Reddit 外链风格)
- 过滤到 OpenWebText 链接来源的页面(Reddit karma ≥ 3 的外链)
- 用 12 个 dumps 得到 17GB 文本
- 对比 WebText 40GB:提示 Common Crawl 覆盖并不完整
- 在 GLUE、SQuAD 等基准上带来提升
4.6 GPT-3(2020):多源混合 + 分类器过滤 + 模糊去重
- GPT-3 论文(数据在 2.2 节):
https://arxiv.org/pdf/2005.14165 - 数据构成:
- 处理后的 Common Crawl
- WebText2(扩展版 WebText)
- (”神秘的”)互联网书籍语料 Books1、Books2
- Wikipedia
- 总规模:570GB(400B tokens)
- Common Crawl 的处理:
- 训练质量分类器区分
{WebText, Wikipedia, Books1, Books2}vs 其他 - 文档级模糊去重(包括 WebText 与基准数据,避免 train-test overlap)
- 训练质量分类器区分
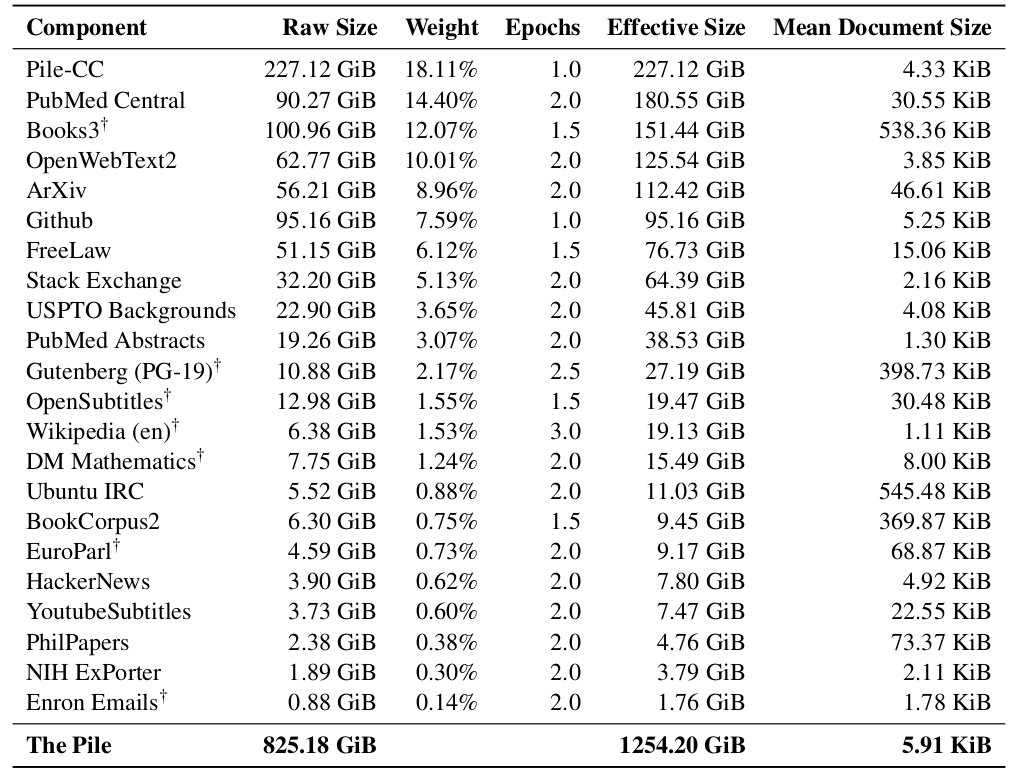
4.7 The Pile(2021):开源社区协作的 22 域高质量语料
- The Pile:
https://arxiv.org/pdf/2101.00027 - 背景:对 GPT-3 的反应,推动开源大模型
- 组织方式:大量志愿者在 Discord 上协作/贡献
- 选取 22 个高质量领域(图):
- 规模:825GB(约 275B tokens)
- 部分来源示例:
- Pile-CC:Common Crawl,使用 WARC +
jusText做 HTML→文本(比 WET 更好) - PubMed Central:500 万论文(NIH 资助要求公开)
- arXiv:自 1991 年的预印本(从 LaTeX 提取)
- Enron Emails:50 万封邮件、150 名高管用户(2002 年安然调查期间公开):
https://www.cs.cmu.edu/~enron/
- Pile-CC:Common Crawl,使用 WARC +

4.7.1 Project Gutenberg:公共领域图书
https://www.gutenberg.org/- 1971 年 Michael Hart 发起,目标是提升文学可访问性
- 2025 年约 7.5 万本书,多为英文
- 只收录版权已清理的书(大多在 public domain)
- PG-19:2019 年前的 Gutenberg 书籍:
https://github.com/google-deepmind/pg19
4.7.2 Books3:影子图书馆数据(高价值也高争议)
- Books3(Presser, 2020):
https://paperswithcode.com/dataset/books3 - 特征:
- 约 19.6 万本书,来自影子图书馆 Bibliotik
- 包含大量当代作者作品(例:Stephen King、Min Jin Lee、Zadie Smith):
https://www.wired.com/story/battle-over-books3/ - 因版权侵权/诉讼已被下架:
https://huggingface.co/datasets/the_pile_books3
影子图书馆(Shadow libraries):https://en.wikipedia.org/wiki/Shadow_library
- 例:LibGen、Z-Library、Anna’s Archive、Sci-Hub
- 绕过版权/付费墙(例:Elsevier)
- 常遭 takedown、诉讼、各国封禁,但往往会被绕过(跨国服务器、镜像等)
- 争议:有人认为”本应自由的知识被付费墙锁住”,影子库提供了公共利益
- 规模(课程中的数字):
- LibGen:~400 万本书(2019)
- Sci-Hub:~8800 万论文(2022)
补充:Meta 使用 LibGen 训练模型(新闻/观点):https://www.forbes.com/sites/danpontefract/2025/03/25/authors-challenge-metas-use-of-their-books-for-training-ai/
4.7.3 StackExchange:接近”真实应用”的问答格式数据
- StackExchange 是用户贡献问答网站集合
- 2008 年从 StackOverflow 开始,扩展到其他主题站点(数学、文学等):
https://stackexchange.com/sites - 用声望、徽章等机制激励参与
- 示例:
https://ell.stackexchange.com/questions/351826/is-he-not-the-carpenters-son-v-s-is-not-he-the-carpenters-son - 随机例子:
https://www.isimonbrown.co.uk/dicestack/ - 为什么有用:
- Q&A 格式天然接近指令微调/真实问题解决
- 还有大量可用于过滤的元数据(用户、票数、评论、徽章、标签等)
- 数据获取:
- XML dump(匿名化,包含元数据):
https://archive.org/details/stackexchange
- XML dump(匿名化,包含元数据):
4.7.4 GitHub:代码与元数据(以及超大规模去重)
- 代码对编程任务有帮助,也常被认为对”推理”有帮助(经验说法)
- GitHub:2008 年成立,2018 年被微软收购
- 随机仓库:
https://gitrandom.digitalbunker.dev/ - 2018 年:至少 2800 万公开仓库:
https://en.wikipedia.org/wiki/GitHub - 仓库内容:
- 是一个目录,不全是代码(还可能有文档、配置、数据等)
- 元数据丰富:用户、issues、提交历史、PR 评论等
- 重复非常多(复制粘贴、fork 等)
GH Archive:https://www.gharchive.org/
- 每小时快照 GitHub events(提交、fork、工单、评论等)
- 也可在 Google BigQuery 上访问
The Stack:https://arxiv.org/pdf/2211.15533
- 用 GHArchive(2015–2022)提取仓库名
git clone1.37 亿个仓库、510 亿个文件(其中 50 亿唯一文件)- 只保留宽松许可证(MIT、Apache 等),用
go-license-detector - 用 MinHash + Jaccard 相似度去近重复
- 结果:3.1TB 代码
4.8 Gopher / MassiveText(2021):规则过滤的大规模网页
- MassiveText(Gopher 训练数据):
https://arxiv.org/pdf/2112.11446(课程代码中引用:gopher) - 备注:Gopher 后来被 Chinchilla(同样未发布)”覆盖”,但其数据描述很有代表性
组件(Components):
- MassiveWeb(后面会更多出现)
- C4
- Books(无细节)
- News(无细节)
- GitHub(无细节)
- Wikipedia(无细节)
MassiveWeb 的过滤步骤:
- 保留英文、去重、避免与测试集重叠
- 质量过滤用手工规则(而非分类器)
- 例:80% 的词至少包含一个字母字符
- 用 Google SafeSearch 做毒性过滤(而不是词表)
结果:10.5TB 文本(但 Gopher 只训练了 300B tokens,约 12%)
4.9 LLaMA(2022):多源混合 + 规则/分类器过滤
- LLaMA 数据:
https://arxiv.org/pdf/2302.13971 - 数据构成与处理:
- CommonCrawl:CCNet 处理;根据是否”像 Wikipedia 的引用”做分类
- C4(更 diverse;回忆:规则过滤)
- GitHub:保留宽松许可证;手工规则过滤
- Wikipedia:2022/6–8,20 种语言,手工过滤
- Project Gutenberg、Books3(来自 The Pile)
- arXiv:移除注释、展开宏、移除参考文献
- Stack Exchange:28 个最大站点,按答案 score 排序
- 总规模:1.2T tokens
复现/扩展:
- Together 的 RedPajama v1:
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T - Cerebras SlimPajama:对 RedPajama v1 去重得到 627B 子集(MinHashLSH):
https://www.cerebras.ai/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama - 旁注:RedPajama v2 基于 84 个 CommonCrawl 快照、过滤很少但包含大量质量信号,总计 30T tokens:
https://github.com/togethercomputer/RedPajama-Data
4.10 RefinedWeb(2023)与 FineWeb:高质量网页抽取 + 去重 +(可选)隐私处理
RefinedWeb:https://arxiv.org/pdf/2306.01116
- 观点:web data is all you need(网页数据足够强)
- 数据示例:
https://huggingface.co/datasets/tiiuae/falcon-refinedweb/viewer/default/train - 用
trafilatura做 HTML→文本抽取(用 WARC 而不是 WET) - 过滤:采用 Gopher 规则;避免 ML 过滤以减少偏置
- 模糊去重:对 5-gram 做 MinHash
- 发布:从 5T tokens 中筛出 600B tokens
FineWeb(对 RefinedWeb 的改进版):https://huggingface.co/datasets/HuggingFaceFW/fineweb
- 使用 95 个 Common Crawl dumps
- URL 过滤 + 语言识别(保留 p(en) > 0.65)
- 过滤:Gopher、C4 以及更多手工规则
- 模糊去重:MinHash
- 隐私:匿名化 email 与公网 IP(PII)
- 结果:15T tokens
4.11 Dolma(2024):多源聚合 + 规则过滤 + 去重
- Dolma:
https://arxiv.org/pdf/2402.00159 - 图(外链):

- 数据来源:
- Reddit:来自 Pushshift(2005–2023),分别收录 submissions 与 comments
- PeS2o:Semantic Scholar 的 4000 万学术论文
- C4、Project Gutenberg、Wikipedia/Wikibooks
Common Crawl 处理:
- 语言识别(fastText),保留英文
- 质量过滤(Gopher、C4 规则),避免模型过滤
- 毒性过滤:规则 + Jigsaw 分类器
- 去重:Bloom filters
结果:3T tokens
4.12 DataComp-LM / DCLM(2024):用”模型过滤”系统化比较数据处理算法
- DataComp-LM(DCLM):
https://arxiv.org/pdf/2406.09179 - 目标:定义一个标准数据集,用于比较不同数据处理/过滤算法
- 把 Common Crawl 处理得到 DCLM-pool(240T tokens)
- DCLM-baseline:用质量分类器从 pool 中筛出子集

4.12.1 模型过滤(Model-based filtering)的正/负样本构造
正样本(200K):
- OpenHermes-2.5(多数由 GPT-4 生成的指令数据):
https://huggingface.co/datasets/teknium/OpenHermes-2.5- 示例:
https://huggingface.co/datasets/teknium/OpenHermes-2.5/viewer/default/train
- 示例:
- ELI5(Explain Like I’m Five):
https://www.reddit.com/r/explainlikeimfive/- 示例:
https://huggingface.co/datasets/sentence-transformers/eli5/viewer/pair/train
- 示例:
负样本(200K):
- RefinedWeb:
https://huggingface.co/datasets/tiiuae/falcon-refinedweb/viewer/default/train
结果:3.8T tokens
实现方式:
- 训练一个 fastText 分类器,并对整个 DCLM-pool 打分
- 该质量分类器在实验中优于其他过滤方法

4.13 Nemotron-CC(2024):在”更多 tokens”与”质量”之间找平衡
- Nemotron-CC:
https://arxiv.org/pdf/2409.02871 - 动机:
- FineWebEdu、DCLM 过滤得过于激进(去掉 90% 数据)
- 需要更多 tokens,但仍希望保持质量
- HTML→文本:使用
jusText(不是trafilatura),因为它能返回更多 tokens
Classifier ensembling(分类器集成):
- 用 Nemotron-340B-instruct 提示评分 FineWeb 文档的”教育价值”,再蒸馏到更快模型
- 叠加 DCLM 分类器
Synthetic data rephrasing(合成数据改写/增强):
- 对低质量数据:用语言模型”改写”使其更像高质量文本
- 对高质量数据:用语言模型生成任务(QA 对、关键点提取等)
结果:
- 总计 6.3T tokens(高质量子集 1.1T)
- 参考:Llama 3 训练 15T,Qwen3 训练 36T
