1 主要功能
基于 WebDataset 的存储格式
采用 WebDataset 作为底层数据集存储方案,支持高效的顺序读取和分布式访问。
超大规模数据集处理
针对多机多卡训练场景深度优化,尤其DP并行,能够处理 PB 级别的超大规模数据集。
数据集混合
支持将多个异构数据集按权重混合或拼接,适用于多任务学习和课程学习场景。
状态管理
提供状态保存与恢复机制,确保训练可中断、可复现、可继续,保证数据迭代的完全一致性。
多模态数据支持
在同一训练流程中处理文本、图像、视频、音频等多种模态数据。
2 基础接口与基础组件
2.1 基础接口
2.2.1 单条数据加载
from megatron.energon import get_train_dataset, get_loader, WorkerConfig
# 创建数据集
ds = get_train_dataset(
'/my/dataset/path',
batch_size=1,
shuffle_buffer_size=100,
max_samples_per_sequence=100,
worker_config=WorkerConfig.default_worker_config(),
)
# 创建数据加载器
loader = get_loader(ds)
# 迭代训练数据
for batch in loader:
# 执行推理、梯度更新等操作
pass
输出示例:
CaptioningSample(
__key__='part_00123/00403.tar/004030195',
image=tensor(...), # 形状: (1, 3, H, W)
caption='...'
)
字段说明:
__key__: 样本标识符,格式为TAR_FILE/INDEX,所有样本均继承自Sampleimage: RGB 图像张量caption: 文本描述
2.2.2 batch加载
loader = get_loader(get_train_dataset(
'/path/to/your/dataset',
batch_size=2,
shuffle_buffer_size=100,
max_samples_per_sequence=100,
worker_config=WorkerConfig.default_worker_config(),
))
for batch in loader:
print(batch)
break
输出的 batch:
batch.__key__: 两个样本的 key 列表batch.image: 形状为(2, 3, H, W)的张量batch.caption: 两个 caption 字符串的列表
默认 TaskEncoder 的批处理行为:
- 张量(tensor): 自动 padding 并 stack 成批量张量
- 列表/字符串: 自动组成 list
- 不做任务相关转换: 不执行 tokenization、图像 resize 等操作
2.2 主要的组件
get_train_dataset
实例化数据集。返回的是一个包含 batching、shuffling、packing 等逻辑的数据集对象。
WorkerConfig
数据加载始终需要 Worker 配置,用于指定多机多卡训练中各 rank 与 worker 的分配方式。不指定的话走default_worker_config() 获取默认配置,其中 default_worker_config 尝试从 torch.distributed 推断
get_loader
用于处理 worker 进程管理。返回的 loader 会调用 TaskEncoder 处理样本,并将处理后的 batch 返回给训练循环。
3 核心概念
3.1 Dataset 层级的批处理
为什么由数据集生成 batch?
在 Energon 中,batch 的生成发生在dataset 层级,区别于 PyTorch 的 DataLoader 层级。
功能实现需要
Energon 的许多功能(如多数据集混合、序列打包等)都是通过数据集包装器(Dataset Wrapper)实现的。Batching 本身就是其中一种包装器,默认的 get_train_dataset 会根据传入参数自动构建合适的组合
状态一致性保证
训练中断后恢复时,需要保证 batch 级别的一致性(包括顺序、shuffle buffer 状态等)。让 Dataset 直接产出 batch 更便于管理和恢复状态。
与传统 PyTorch 的区别
| 方面 | PyTorch | Energon |
|---|---|---|
| Dataset 职责 | 返回单条样本 | 返回整个 batch |
| Batch 生成 | DataLoader 负责 | Dataset 层完成 |
| 功能扩展 | 通过 DataLoader 参数 | 通过 Dataset Wrapper |
3.2 shuffle 参数设置
必须显式设置 shuffle_buffer_size 和 max_samples_per_sequence?
基于顺序化的 WebDataset,为保证充分的随机打乱,需要显式设置这些参数:
shuffle_buffer_size(shuffle的缓冲区大小)
- 过小:随机访问比例增加,数据加载速度变慢
- 过大:随机性下降,需要更大缓冲区补偿,增加内存占用与恢复时间
- 推荐:对于图像数据集,设为 100 通常能在随机性与性能间取得良好平衡
max_samples_per_sequence(序列最大样本数)
- 控制从单个数据分片(shard)连续读取的最大样本数
- 应设置为足够大的值,减少磁盘寻道次数
- 根据实际需求调整,配合 shuffle_buffer_size 使用
4 数据流 DataFlow
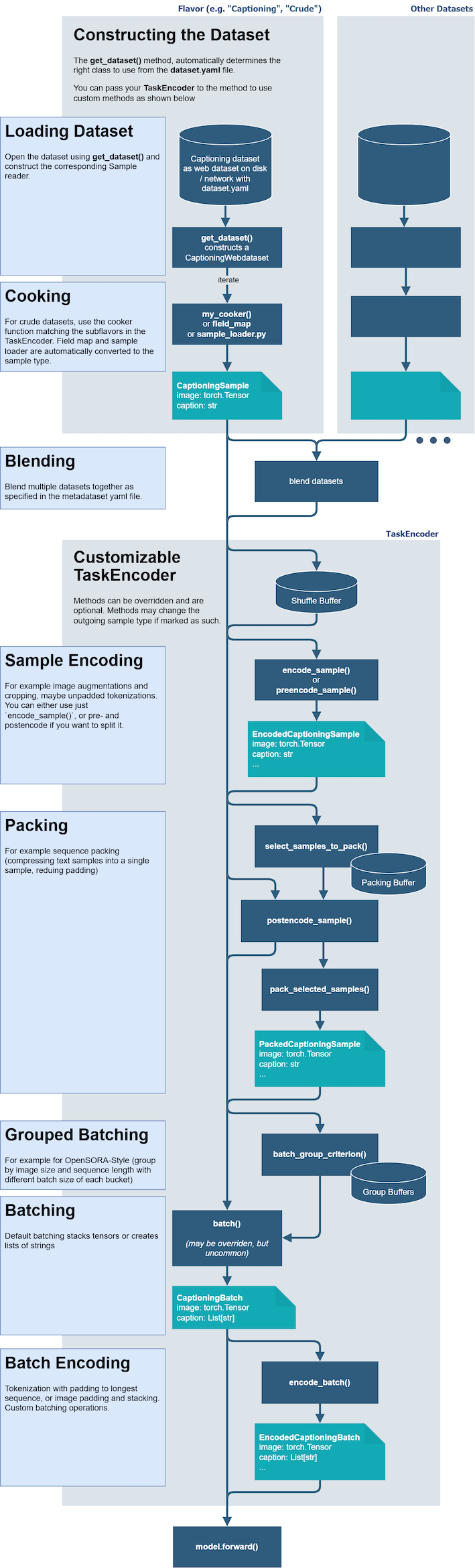
Energon 的数据流分为两大部分: 数据集构建 和 TaskEncoder 处理。
4.1 数据集构建阶段
1. Loading Dataset(加载数据集)
使用 get_dataset() 打开 WebDataset,创建 crude dataset。通过 cooker/field_map/sample_loader 将原始条目转换为样本。
输出: Sample 对象(例如 CaptioningSample(image, caption))
2. Blending(数据集混合)
根据 metadataset.yaml 配置,按权重混合(blend)或拼接(concat)多个数据集。
4.2 TaskEncoder 处理阶段
TaskEncoder 控制数据送入模型前的完整处理流程:
1. Shuffle Buffer(样本打乱)
维护一个缓冲区,随机打乱样本顺序。
2. encode_sample() / preencode_sample()(单样本编码)
执行图像增强、tokenize 等单样本级别的转换。
3. postencode_sample()(后编码)
在确定打包方案后执行的后处理。
4. Packing(样本打包)
典型应用: 序列打包(sequence packing),将多个短文本合并为一个样本以减少 padding。
- 使用
select_samples_to_pack()选择要打包的样本 - 使用
pack_selected_samples()执行实际打包
输出: PackedSample
5. Grouped Batching(分组批处理)
类似 OpenSORA 风格: 按图像尺寸/序列长度分 bucket,每个 bucket 使用不同的 batch size,减少 padding 浪费。
6. Batching(批处理)
默认逻辑:
- 张量: 堆叠(stack)
- 字符串: 转换为列表
输出: SampleBatch
7. Batch Encoding(批次编码)
在 batch 维度执行最终处理:
- 文本: tokenize + padding 到最长长度
- 图像: resize/pad/stack
- 其他任务特定操作
输出: EncodedBatch
8. Model Forward
最终 EncodedBatch 被送入 model.forward()。
5 数据集准备
5.1 数据集结构
WebDataset 格式的数据集目录结构如下:
dataset/
├── shards/
│ ├── shard_0000.tar
│ ├── shard_0001.tar
│ └── ...
└── .nv-meta/
├── dataset.yaml
└── split.yaml
5.2 准备流程
使用命令行工具初始化数据集:
energon prepare ./
交互式:
Ratio: 8,1,1
Dataset class: CaptioningWebdataset
Field map: Yes
image: jpg
caption: txt # 如果 txt 文件直接包含 caption
# 或者
caption: json[caption] # 如果 .json 文件包含 {"caption": "..."}
5.3 元数据文件
dataset.yaml
sample_type:
__module__: megatron.energon
__class__: CaptioningSample
field_map:
image: jpg
caption: txt
定义了样本类型和字段映射关系。
split.yaml
exclude: []
split_parts:
train:
- shards/shard_000.tar
- shards/shard_001.tar
val:
- shards/shard_002.tar
test:
- shards/shard_003.tar
定义了数据集的划分(训练集/验证集/测试集)及其比例。
5.4 多源数据集混合
通过 metadataset.yaml 配置文件混合多个数据集:
__module__: megatron.energon
__class__: MetadatasetV2
splits:
train:
blend:
- weight: 5
path: ./coco
- weight: 2
path: ./coyo
val:
path: ./coco
test:
path: ./coyo
5.5 数据集组织策略
单体数据集(Monolithic Dataset)
将所有信息(文本、图像、视频等)打包到同一个 tar 文件中。
优点:
- 顺序 IO,加载速度快
- 数据管理简单
适用场景:
- 样本大小相对均匀
- 媒体文件较小
多体数据集(Polylithic Dataset)
主数据集(如 JSONL)与媒体文件分离存储。
优点:
- 媒体特别大(如长视频)时,主数据集保持轻量
- 一份媒体可对应多份标签,便于重用
适用场景:
- 大型媒体文件
- 需要多标签/多任务学习
5.6 数据分片策略
性能考虑:
- 分片越少,加载速度越快
- 理论上可以将所有数据打包在一个 tar 中
实际限制:
- 文件系统可能有大小限制
- 工具链可能有处理上限
推荐配置:
- 总分片数 < 10,000
- 单个分片大小适中(根据存储系统调整)
7 状态保存与恢复 save & restore
为什么需要保存状态?
主要是,只存储全局的 step/epoch 无法还原到完全一致的下一条样本。所以需要把将数据加载的内部状态序列化,包括:
- 当前数据源游标(shard/tar 文件位置、样本索引)
- Shuffle buffer 的内容与 RNG 状态
- Blend/重复次数进度(metadataset/epochized blending)
- Packing 的队列余量
- 采样器/迭代器内部的随机数种子与次序
保存状态:
from megatron.energon import get_train_dataset, get_savable_loader, WorkerConfig
ds = get_train_dataset(..., worker_config=wc)
loader = get_savable_loader(ds)
# 训练循环中
for step, batch in enumerate(loader):
# 执行训练步骤
if should_checkpoint(step):
state = loader.save_state_rank() # 与当前 DP rank 绑定
# 将状态保存到 checkpoint
# torch.save(state, path)
恢复状态:
ds = get_train_dataset(..., worker_config=wc) # worker_config 必须与保存时一致
loader = get_savable_loader(ds)
# 从 checkpoint 加载状态
state = torch.load(path)['loader_states'][dp_rank]
loader.restore_state_rank(state)
# 继续迭代,从中断处的下一条样本开始
for batch in loader:
# 训练逻辑
pass
注意事项:
- 恢复时的
worker_config(特别是 DP rank/size)必须与保存时保持一致 - 不同 DP rank 的状态需要分别保存和恢复
8 数据解码 Data Decode
Data Decode是指在Sample 之前, 将原始字节流转换为可用的 Python 对象:
- 文本: 字节流 → Python 字符串
- JSON: 字节流 → Python 字典/列表
- 图像/视频/音频: 字节流 → 张量
- Torch PTH 文件: 字节流 → torch.Tensor
- NPY 文件: 字节流 → numpy.ndarray
数据流:
tar 文件字节流 → Data Decode → Python 对象 → Sample Loading → Task Encoder
8.1 版本7.0及之后
在 TaskEncoder 中通过 SampleDecoder 指定解码方式:
class MyTaskEncoder(DefaultTaskEncoder):
decoder = SampleDecoder(image_decode="pilrgb")
支持的解码选项:
"pilrgb": 使用 PIL 解码为 RGB"torchrgb": 解码为 torch RGB 张量- 自定义解码函数
8.2 版本7.0 之前
通过 get_train_dataset 的 auto_decode 参数控制:
ds = get_train_dataset(
path,
batch_size=4,
auto_decode=True, # 或 False
)
局限性:
- 无法扩展新格式
- 缺少灵活的配置选项,即不能自己实现SampleDecoder 对Decoder进行自定义是心
- 不支持 guess_content 等高级功能
8.3 视频/音频解码示例
内置视频和音频解码功能,支持 MP4、MP3、WAV 等格式。
核心组件:
- 集成 fastseek 库: 快速从长视频提取子片段
- 底层使用 PyAV: 依赖 ffmpeg 进行实际解码
基础用法:
decoder = SampleDecoder(av_decode="AVDecoder")
提取视频片段:
# 提取前 2 秒和第 4-6 秒的片段
dat = av_decoder.get_clips(
video_clip_ranges=[(0, 2), (4, 6)],
video_unit="seconds",
)
print(dat.video_clips[0].shape) # 第一个片段
print(dat.video_clips[1].shape) # 第二个片段
均匀采样多个片段:
from megatron.energon.av import get_clips_uniform
dat = get_clips_uniform(
av_decoder=av_decoder,
num_clips=5, # 提取 5 个片段
clip_duration_seconds=3, # 每个片段 3 秒
request_audio=True # 同时返回音频
)
效果:
- 将视频均匀分成 5 段,每段 3 秒
- 第一个片段从 0 秒开始,最后一个片段在结尾结束
- 同时返回对应的音频片段
均匀采样单帧:
frames = av_decoder.get_single_frames_uniform()
返回均匀采样的帧张量(而非视频段)。
解码完整内容:
dat = av_decoder.get_video() # 仅视频
dat = av_decoder.get_audio() # 仅音频
dat = av_decoder.get_video_with_audio() # 视频+音频
延迟解码机制:
AVDecoder 提供延迟解码功能,只在真正需要时才解码,避免加载整个视频浪费资源。
典型应用场景:
- 视频分类: 均匀抽取几个片段
- 视频问答: 根据问题提取特定时间片段
- 视频检索: 均匀抽帧做特征提取
9 TaskEncoder 处理
TaskEncoder 是 Energon 的最核心组件,主要是描述样本在数据管线各阶段的处理方式
9.1 基础概念
默认实现:
如果不显式指定,将使用 DefaultTaskEncoder。
自定义方式:
继承 DefaultTaskEncoder 并重写相应方法,然后通过 get_train_dataset 或 get_val_dataset 传入。
9.2 接口
1. cook_crude_sample(可选)
def cook_crude_sample(self, sample: Union[T_sample, CrudeSample]) -> T_sample
使用 crude 数据集时定义,将粗样本(原始字节/简单字典)转换为目标样本类型, 例如VQA caption等目标
2. encode_sample
def encode_sample(self, sample: T_sample) -> T_encoded_sample
对单条样本进行变换,如图像增强、文本 tokenize 等。
如果需要配合 packing 延后部分操作, 需要改用 preencode_sample + postencode_sample 组合
3. preencode_sample(可选)
def preencode_sample(self, sample: T_sample) -> T_sample
作为 encode_sample 的替代,在选择要packing 前进行初步处理, 要和 postencode_sample 一起使用
4. select_samples_to_pack(可选)
PackingCaptioningTaskEncoder 样例实现:
def select_samples_to_pack(self, samples: List[CaptioningSample]) -> List[List[CaptioningSample]]:
# Do something intelligent here, e.g. sort by caption length and concat where possible.
# This could be better, but it's just an example.
samples.sort(key=lambda x: len(x.caption))
groups = []
while len(samples) > 0:
batch = []
caption_len = 0
while len(samples) > 0 and caption_len + len(samples[0].caption) < self.max_length:
sample = samples.pop(0)
batch.append(sample)
caption_len += len(sample.caption)
groups.append(batch)
return groups
配置:
在 loader 初始化时设置 packing_buffer_size > 0:
ds = get_train_dataset(
...,
packing_buffer_size=1000, # buffer 越大,越容易找到合适的组合
)
Energon 会先将数据放入 buffer,再调用 select_samples_to_pack 进行选择。
返回要打包的样本分组,这里可以实现packing策略
5. postencode_sample(可选)
def postencode_sample(self, sample: T_sample) -> T_encoded_sample
打包后,接着preencoder_sample 处理
6. pack_selected_samples(必须,与 select 配套)
def pack_selected_samples(self, samples: List[T_encoded_sample]) -> T_batch_sample
将一组样本压缩为单个样本(packing 产物), 一般是拼接 7. batch
def batch(self, batch: List[T_encoded_sample]) -> T_raw_batch
批处理(collate):
- 默认对张量做 padding + 堆叠
- 非张量字段聚合为列表
8. encode_batch DefaultTaskEncoder 示例:
@stateless
def encode_batch(self, batch: T_raw_batch) -> Union[T_batch, Generator[T_batch, None, None]]:
"""Encode a batch of samples. The default implementation converts to the
_encoded_batch_type."""
if self._batch_type is None or self._raw_batch_type == self._batch_type:
return batch
if is_dataclass(batch):
fields = {field.name: getattr(batch, field.name) for field in dataclasses.fields(batch)}
elif isinstance(batch, tuple) and hasattr(batch, "_fields"):
fields = {field: getattr(batch, field) for field in batch._fields}
elif isinstance(batch, dict):
fields = batch
else:
raise ValueError("Unrecognized sample type.")
if issubclass(self._batch_type, dict):
return fields
elif dataclasses.is_dataclass(self._batch_type) or issubclass(self._batch_type, tuple):
# DataClass or NamedTuple
return self._batch_type(**fields)
else:
raise ValueError("Unrecognized encoded sample type.")
对整个 batch 进行变换:
- 整批 tokenize
- 整批图像 pad/stack
- 构造 attention_mask / loss_mask 等
9. pin_memory(DataLoader 阶段)
通过 get_loader 将数据从 worker 进程送回主进程时:
- 如果 batch 基于
Batchdataclass: 调用其pin_memory()方法 - 如果不是 dataclass: 使用 PyTorch 默认的 pinning 逻辑
为什么需要 pin memory?
“锁页内存(pinned memory)”是指操作系统不会将这块内存换到 swap。
好处: GPU 可以直接通过 DMA 访问,CPU 到 GPU 的数据拷贝更快。
典型用法:
for batch in loader:
batch = batch.pin_memory() # 或 DataLoader 自动调用
batch = batch.to(device, non_blocking=True)
注意: 此操作必须在主进程执行,不能在 worker 进程中进行。
9.3 完整示例
from dataclasses import dataclass
from typing import Callable, List, Optional
import torch
from transformers import PreTrainedTokenizerBase as Tokenizer
from megatron.energon import (
Batch, CaptioningSample, DefaultTaskEncoder,
SampleDecoder
)
# 中间态批(collate 后、encode_batch 前)
@dataclass
class CaptioningRawBatch(Batch):
image: torch.Tensor # (n, c, h, w)
caption: List[str] # (n,)
# 最终送入模型的批
@dataclass
class CaptioningBatch(Batch):
images: torch.Tensor # (n, c, h, w)
text_tokens: torch.Tensor # (n, L)
text_attn_mask: torch.Tensor # (n, L)
class CaptioningTaskEncoder(
DefaultTaskEncoder[
CaptioningSample,
CaptioningSample,
CaptioningRawBatch,
CaptioningBatch
]
):
"""图像描述任务编码器"""
# 声明解码器: 图像→RGB torch.Tensor
decoder = SampleDecoder(image_decode="torchrgb")
def __init__(
self,
tokenizer: Tokenizer,
image_transform: Optional[Callable[[torch.Tensor], torch.Tensor]] = None,
max_length: int = 128,
):
super().__init__(batch_type=CaptioningRawBatch)
self.tokenizer = tokenizer
self.image_transform = image_transform
self.max_length = max_length
def encode_sample(self, sample: CaptioningSample) -> CaptioningSample:
"""单样本级处理: 图像增强/变换"""
if self.image_transform is not None:
sample.image = self.image_transform(sample.image)
return sample
def batch(self, samples: List[CaptioningSample]) -> CaptioningRawBatch:
"""批处理"""
return CaptioningRawBatch.from_samples(samples)
def encode_batch(self, batch_data: CaptioningRawBatch) -> CaptioningBatch:
"""整批编码: 一次性 tokenize"""
tokenized = self.tokenizer(
batch_data.caption,
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors="pt",
)
return CaptioningBatch.derive_from(
batch_data,
images=batch_data.image,
text_tokens=tokenized["input_ids"],
text_attn_mask=tokenized["attention_mask"],
)
10 并行策略
Energon 主要支持DP并行
分布式参数说明:
Energon 按照数据并行(Data Parallel, DP)维度划分数据:
world_size: 数据并行的总路数(有多少份不同的数据流)rank: 当前数据流的编号(0 ~ world_size-1)num_workers: 每个进程的 DataLoader 子进程数(CPU worker,用于解码/IO)
Energon 只关心DP维度,不需要将 TP /PP /CP 等计入 world_size。
数据并行(DP)
Energon 直接支持,通过 WorkerConfig 指定:
- 确保每个处理器获得不同的数据子集
- 通过 rank 和 world_size 控制分片
流水线并行(PP)
数据通常仅在第一个流水线并行 rank 上加载,然后在组内传播。Energon 不需要特别考虑。
张量并行(TP)
数据加载器在多个设备上加载相同的输入数据。一般加载一次数据并使用 torch.distributed 分发,不涉及 Energon 逻辑。
10.1 并行配置示例
8 GPU 配置示例:
Global Rank 0: DP=0 (组A), PP=0, TP=0
Global Rank 1: DP=0 (组B), PP=0, TP=1
Global Rank 2: DP=X, PP=1, TP=0
Global Rank 3: DP=X, PP=1, TP=1
Global Rank 4: DP=1 (组A), PP=0, TP=0
Global Rank 5: DP=1 (组B), PP=0, TP=1
Global Rank 6: DP=X, PP=1, TP=0
Global Rank 7: DP=X, PP=1, TP=1
数据流:
DP组A(数据子集A):
Rank 0: DP=0, PP=0, TP=0 ← 加载数据
↓ 流水线传递
Rank 2: DP=X, PP=1, TP=0 ← 接收数据
Rank 4: DP=1, PP=0, TP=0 ← 加载数据
↓ 流水线传递
Rank 6: DP=X, PP=1, TP=0 ← 接收数据
DP组B(数据子集B):
Rank 1: DP=0, PP=0, TP=1 ← 加载数据(与Rank 0相同,TP副本)
↓ 流水线传递
Rank 3: DP=X, PP=1, TP=1 ← 接收数据
Rank 5: DP=1, PP=0, TP=1 ← 加载数据(与Rank 4相同,TP副本)
↓ 流水线传递
Rank 7: DP=X, PP=1, TP=1 ← 接收数据
状态保存策略:
- 只需存储 DP 组 A 的状态(Rank 0 和 4)
- Rank 1 和 5 具有相同状态(TP 副本)
状态恢复策略:
- Rank 0、1、4、5 需要接收状态
- 其他 rank 不需要加载数据
10.2 完整代码示例
import torch
from megatron.energon import get_train_dataset, get_savable_loader, WorkerConfig
# 初始化进程组
torch.distributed.init_process_group(backend='nccl')
# 获取各维度的 rank
global_rank = torch.distributed.get_rank()
data_parallel_rank = [0, 0, None, None, 1, 1, None, None][global_rank]
pipeline_parallel_rank = [0, 0, 1, 1, 0, 0, 1, 1][global_rank]
tensor_parallel_rank = [0, 1, 0, 1, 0, 1, 0, 1][global_rank]
# 创建数据并行组
if global_rank in (0, 4):
data_parallel_group = torch.distributed.new_group(ranks=[0, 4])
elif global_rank in (1, 5):
data_parallel_group = torch.distributed.new_group(ranks=[1, 5])
else:
data_parallel_group = None
if data_parallel_rank is not None:
assert pipeline_parallel_rank == 0, "仅流水线并行 rank 0 加载数据"
# 配置 worker
worker_config = WorkerConfig(
rank=data_parallel_rank,
world_size=torch.distributed.get_world_size(data_parallel_group),
num_workers=3,
data_parallel_group=data_parallel_group,
)
# 创建加载器
loader = get_savable_loader(get_train_dataset(
'coyo-coco-dataset.yaml',
batch_size=4,
shuffle_buffer_size=100,
max_samples_per_sequence=100,
worker_config=worker_config,
))
# 训练循环
for i, batch in zip(range(10), loader):
print(batch)
break
# 保存状态(仅第一个 TP rank)
if tensor_parallel_rank == 0:
state = loader.save_state_rank()
torch.save(state, f"dataloader_rank{data_parallel_rank}.pt")
# 恢复状态
if data_parallel_rank is not None:
assert pipeline_parallel_rank == 0, "仅流水线并行 rank 0 加载数据"
# 创建新加载器
loader = get_savable_loader(get_train_dataset(
'coyo-coco-dataset.yaml',
batch_size=4,
shuffle_buffer_size=100,
max_samples_per_sequence=100,
worker_config=worker_config,
))
# 加载并恢复状态
state = torch.load(f"dataloader_rank{data_parallel_rank}.pt")
loader.restore_state_rank(state)
# 继续训练
for batch in loader:
# 训练逻辑
pass