1 Pre-Norm 与 Post-Norm 结构
所有现代的大语言模型(LMs)都采用 Pre-Norm 结构
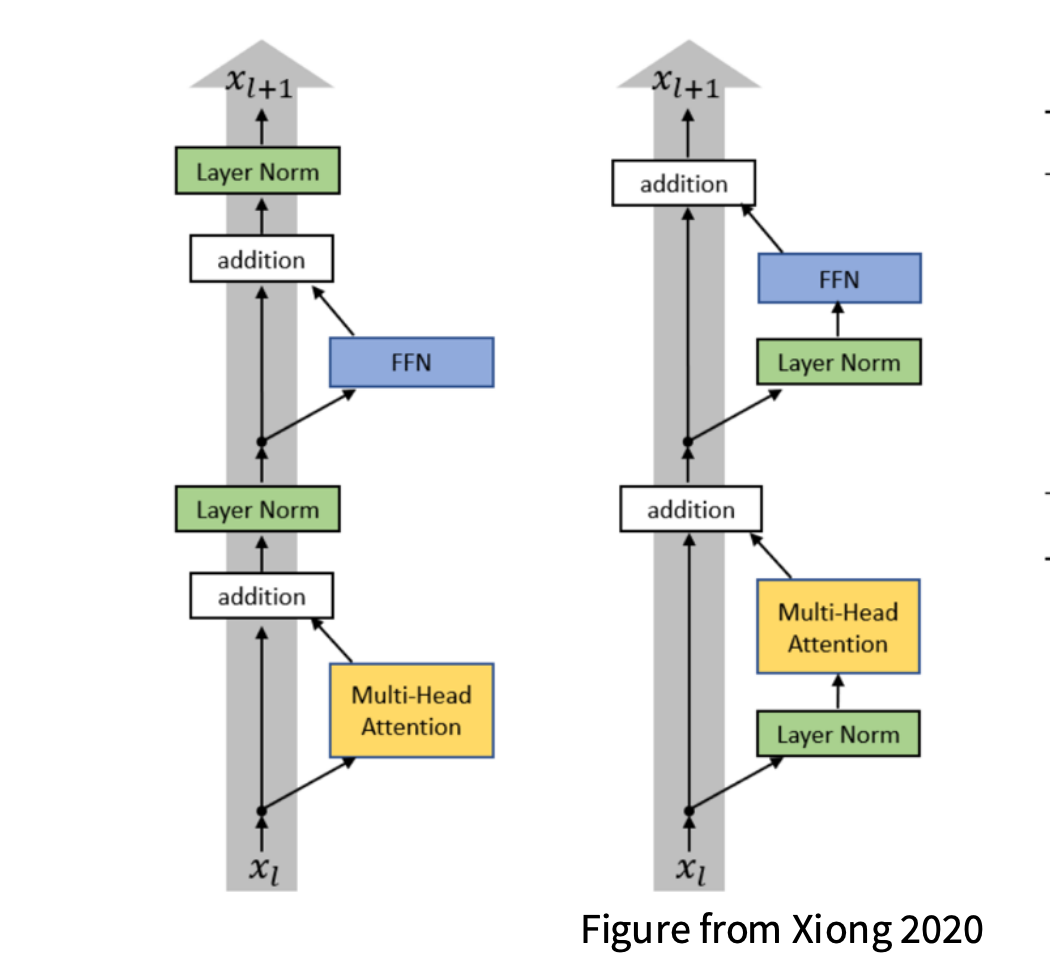
左图为 Post-Norm 结构,即 LayerNorm 放在残差连接(addition)之后
也就是说,每个子层(Self-Attention 或 FFN)计算完,再执行 LayerNorm。
这种结构最早由 Vaswani et al., 2017《Attention is All You Need》 提出。
右图为 Pre-Norm 结构,即 先归一化,再执行子层计算,最后加残差。 这是后来为了解决深层网络训练时的 梯度消失 / 爆炸问题 而改进的版本
2 Pre-LayerNorm 的提出背景
“Pre-LayerNorm(预归一化)” 是 Transformer 结构在深层化和大规模化过程中的关键改进。 早期研究者在 2019–2020 年左右提出这一结构,最初的动机是简化训练过程、提升稳定性
2.1 原始提出时的优势(Original stated advantage)
Removing warmup
最初提出 Pre-LayerNorm 的直接优势在于:
可以在训练初期使用较高的学习率,而不需要学习率 warmup 阶段
在标准 Post-Norm Transformer(LayerNorm 在残差之后)中:
- 深层网络的梯度在前期容易爆炸;
- 所以训练时需要用一个 学习率 warmup 调度器:先用极小学习率,再缓慢升高;
- 否则模型容易发散。
而采用 Pre-Norm 后:
- 每个子层输入先经过 LayerNorm;
- 反向传播的梯度更平稳;
- 训练初期更稳定,可减少甚至移除 warmup
2.2 数学解释
对于任意子层函数 $F(x)$, Post-Norm 与 Pre-Norm 的计算方式分别为:
\[\text{Post-Norm: } y = \text{LayerNorm}(x + F(x))\] \[\text{Pre-Norm: } y = x + F(\text{LayerNorm}(x))\]Pre-Norm 在前向传播时就对输入做归一化 使得每个层的梯度在反向传播时保持数值尺度稳定
3 现代理解与实践(Today)
Stability and larger LRs for large networks
随着模型规模不断增大(如 GPT-3、PaLM、LLaMA 等),Pre-Norm 的真正价值被重新认识
- 更强的训练稳定性 Pre-Norm 能显著缓解梯度消失/爆炸问题,即使上百层也能正常收敛。
- 支持更大的学习率 (larger LRs) 由于 LayerNorm 放在每个子层的输入端,梯度被“标准化”后传播,可安全使用更高的学习率。
- 大模型训练更容易 在现代大模型(尤其是 Decoder-only 架构)中,几乎所有都采用 Pre-Norm 以保证可扩展性。
4 Pre-Norm 到 Post-Norm 的过程
| 时期 | 主要理由 | 效果 |
|---|---|---|
| 最初(2020 前后) | 可以移除或缩短 warmup 阶段 | 提升初期训练稳定性 |
| 现在(2023+) | 提高深层网络梯度稳定性,允许更大学习率 | 大模型训练稳定、高效 |