Transformer 自身并不知道序列的顺序,位置编码就是语言模型补齐“谁在前谁在后”的手段。 这篇笔记把常见做法与 RoPE(Rotary Positional Embedding)的思路串起来,方便日后复习与引用。
1 为什么位置编码仍然关键
多头注意力的打分只依赖 $QK^\top$,如果不给 token 附加位置信息,模型无法区分 “we know” 与 “know we”。 因此任何大模型都必须解决:如何在保持可泛化性的同时,不破坏注意力的内积结构。
2 三种经典做法回顾
2.1 Sine embeddings(正弦位置编码)
\[PE_{(pos,2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right), \quad PE_{(pos,2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)\]- Transformer 论文里的默认方案,不需要额外参数。
- 不同维度使用不同频率,理论上可由线性组合近似出相对位置信息。
- 长序列外推能力一般,且注意力得分会混入 $\langle v_x, PE_y\rangle$ 之类的交叉项,无法做到真正的相对不变性。
2.2 Absolute embeddings(绝对位置编码)
\[Embed(x, i) = v_x + u_i\]- 直接给每个位置 $i$ 学一个向量 $u_i$,最易实现。
- GPT-1/2/3、OPT 等早期模型沿用这个设定。
- 优点是训练期表现好;缺点是过度依赖绝对位置,序列一旦变长就失效。
2.3 Relative embeddings(相对位置编码)
\[e_{ij} = \frac{x_i W^Q \left(x_j W^K + a_{ij}^K\right)^\top}{\sqrt{d_z}}\]- 在注意力分数里加入相对偏移向量 $a_{ij}$,更接近语言结构。
- 被 T5、Gopher、Chinchilla 等采用。
- 仍需显式构造偏移矩阵,且打分公式不再是纯内积形式,计算成本高。
3 RoPE 想解决的两件事
理想目标是让注意力只依赖相对距离 $(i-j)$:
\[\langle f(x,i), f(y,j) \rangle = g(x, y, i-j)\]- 正弦编码会产生词向量与位置向量的交叉项,失去纯相对性。
- 绝对编码完全锁死在训练长度。
- 传统相对编码需要额外张量,无法直接套进轻量的注意力实现。
RoPE 的洞察是:旋转操作的内积只与相对角度有关,因此可以优雅地把“位置差”编码进 $Q/K$。
4 把位置变成旋转:RoPE 的构造
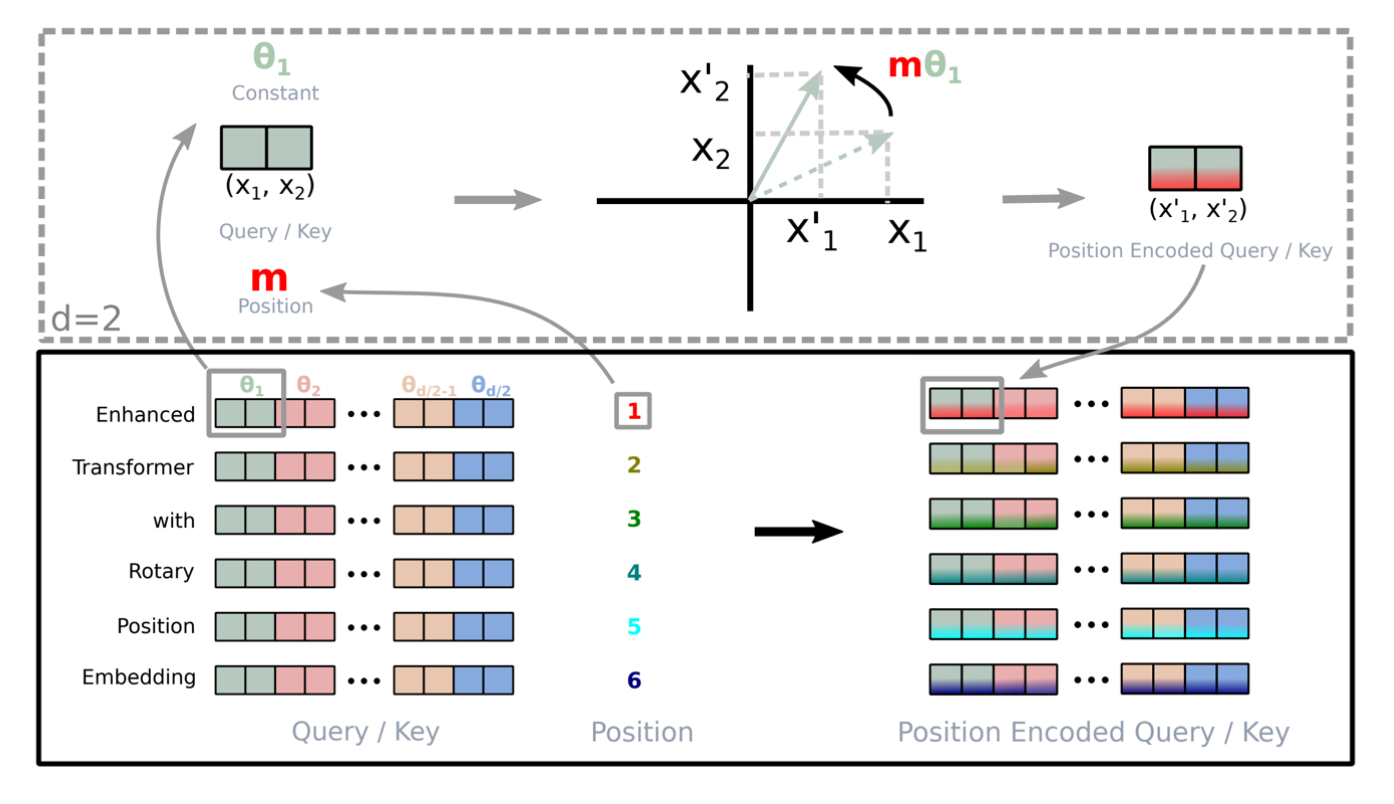
- 将隐空间拆成若干二维平面 $(x_{2i-1}, x_{2i})$。
- 对第 $i$ 个平面执行二维旋转: \(\text{RoPE}(x_{2i-1}, x_{2i}, \theta_i) = \begin{pmatrix} x_{2i-1}\cos \theta_i - x_{2i}\sin \theta_i \\ x_{2i-1}\sin \theta_i + x_{2i}\cos \theta_i \end{pmatrix}\)
- 角度 $\theta_i$ 采用与正弦编码类似的多频率调度——低维旋转快,高维旋转慢。
结果是:每个 token 的向量好比被投射到多个复平面里按不同频率旋转。两个位置的向量旋转后再求内积,得到的分数天然只与角度差(也就是相对位置)相关,无需额外偏移矩阵。
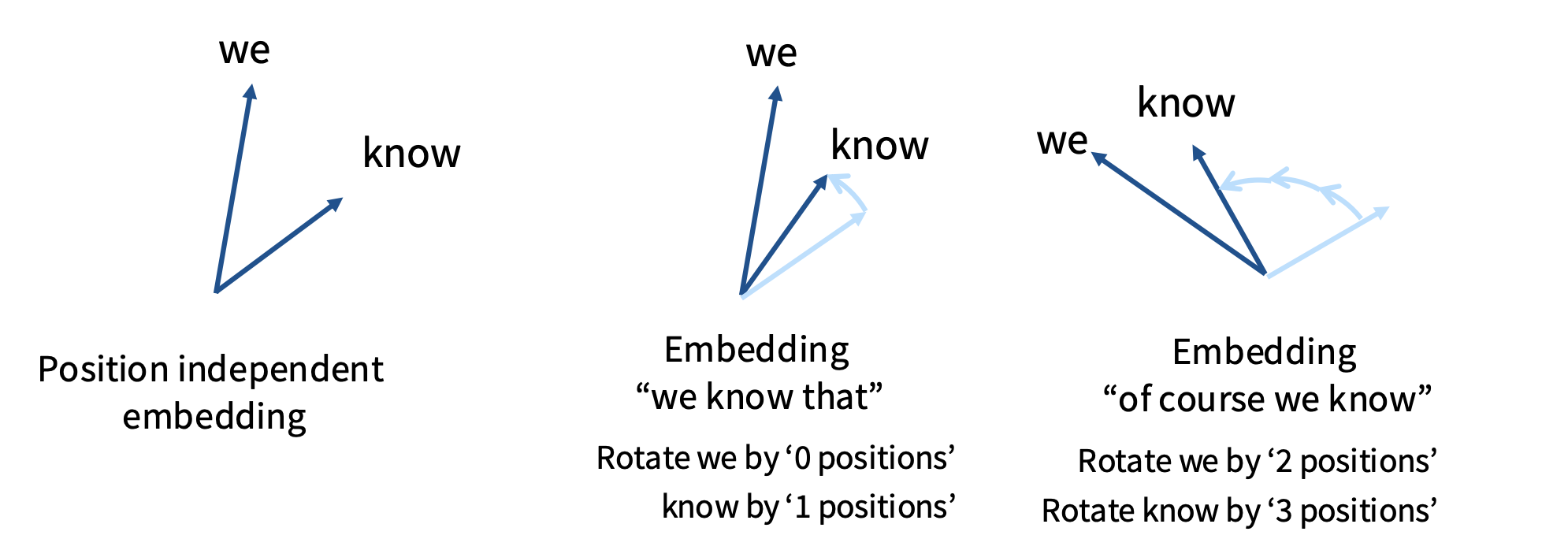
- 无旋转时,“we” 与 “know” 在任何语序下都对齐,模型无法判断先后。
- 加入旋转后,第 $t$ 个 token 会被旋转 $t$ 个单位角度,序列的相对顺序被编码进角度差。
- 距离越远,累积的旋转越大;注意力分数随即感知到“远近”。
参考:https://spaces.ac.cn/archives/8265/comment-page-1
5 在注意力层注入旋转,获得位置平移不变性
- RoPE 不是在 embedding layer 里加向量,而是在 每一层注意力 里对 $Q$、$K$ 做旋转。
- 这样就算 token embedding 本身不含绝对位置信息,每层的注意力仍然能通过“旋转差”感知顺序。
- 因为所有 token 一起平移时旋转角度整体平移,角度差保持不变,模型对序列整体平移保持 position invariance。
6 关键信息速记
- 正弦、绝对、相对编码各有侧重:实现简单 vs. 泛化 vs. 内积友好。
- RoPE 的关键操作是“把位置信息换成复平面旋转”,从而保持注意力的内积结构。
- 旋转频率沿维度递减,兼顾局部和全局依赖。
- 在每层 Attention 中处理 $Q/K$,比只在输入端加入位置更加稳健、可叠加。