MoE 三个问题:如何并行、为何随机、怎样稳定
1. MoE 的模型并行 vs 数据并行
MoE 训练通常把“专家”视为模型并行单元,再与数据并行组合。下图直观展示了权重如何在 data parallel、model parallel 与 expert parallel 之间拆分:

- Model Parallel:同一批 token 被切到不同设备,各自负责部分 FFN/attention 计算;适合巨型专家参数。
- Data Parallel:复制一份完整模型,分批处理不同样本;用来堆 throughput。
- Expert Parallel:把专家实例平均分发到多卡,token 依据路由结果被 permute 到对应设备。
实战中常出现“三明治”拓扑:DP 包住 EP,内部再穿插张量/流水并行。调度的目标是让每块 GPU 都能在通信与计算之间保持高利用率,典型做法是:
- 先在 DP 维度做梯度 AllReduce,保证副本同步;
- 再在 EP 维度做 All-to-All,把 token 送到对应专家,再把结果按顺序拼回;
- 对巨大 FFN 再叠加张量并行,把矩阵乘拆给多卡,缓解显存。
如果忽略通信层设计,只简单地增加专家数量,很容易出现“算力被 All-to-All 吃掉”的情况,吞吐反而下降。因此很多实现会引入 token bucketing、分层专家组(hierarchical routing)等技巧,把通信限制在较小的组内,减少跨机 hop。
2. 稀疏专家的矩阵计算
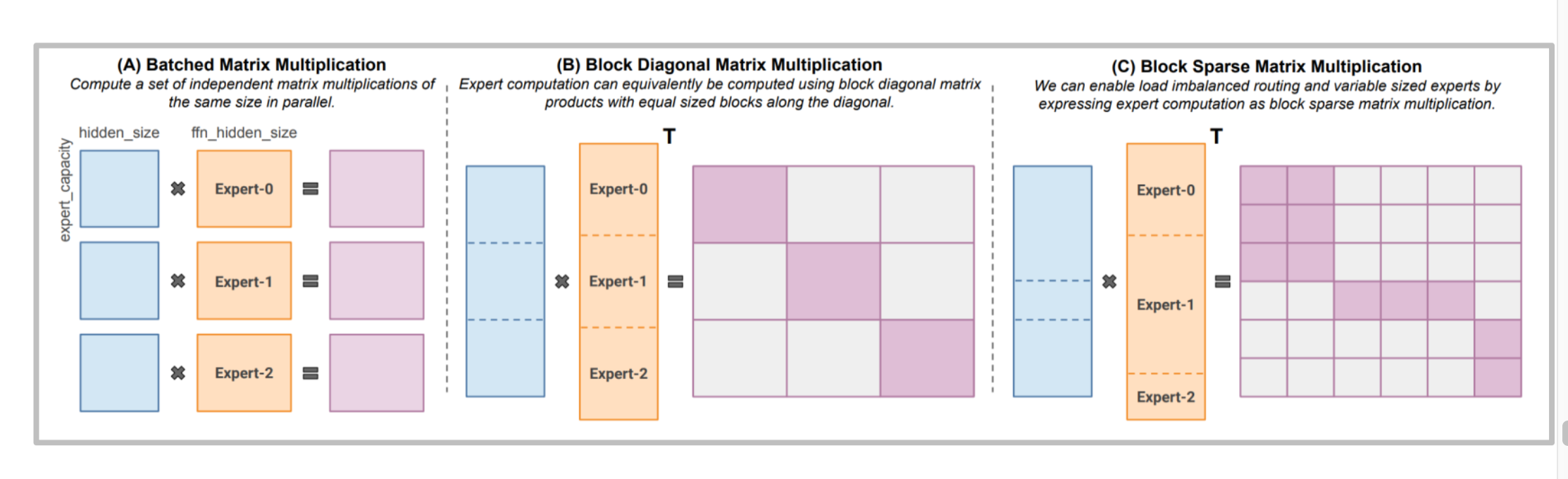
稀疏 MoE 的矩阵乘拆分成两步:先用 gate 选出 top-k 专家,再在这些专家上做小规模 dense matmul。得益于稀疏激活,每个 token 只触发 1~2 个专家,推理 FLOPs 与激活存储都等比例下降。瓶颈转而变成“如何把不同 token 打包给同一张卡”,这就需要高效的 permute/un-permute kernel。
常见的执行顺序如下:
- Router 计算 logits(通常是
hidden @ W_gate),做 softmax; - 选出 top-k 专家并记录 score,填入 Permute Buffer;
- 用分段 prefix-sum 计算每个专家要处理的 token 范围,完成 All-to-All;
- 专家内部执行
token_chunk @ W_in、GELU、@ W_out; - 把结果按路由系数加权,再以逆 permute 写回。
这套流程决定了 kernel 设计与批量大小密切相关:batch/k 超小会导致每个专家只拿到零星 token,GPU 无法被充分填满;batch 太大又会触发容量裁剪,浪费梯度信号。生产中通常会配合动态 token bucketing,把长度接近的序列聚在一起,减少碎片。
3. MoE 为什么更“随机”?
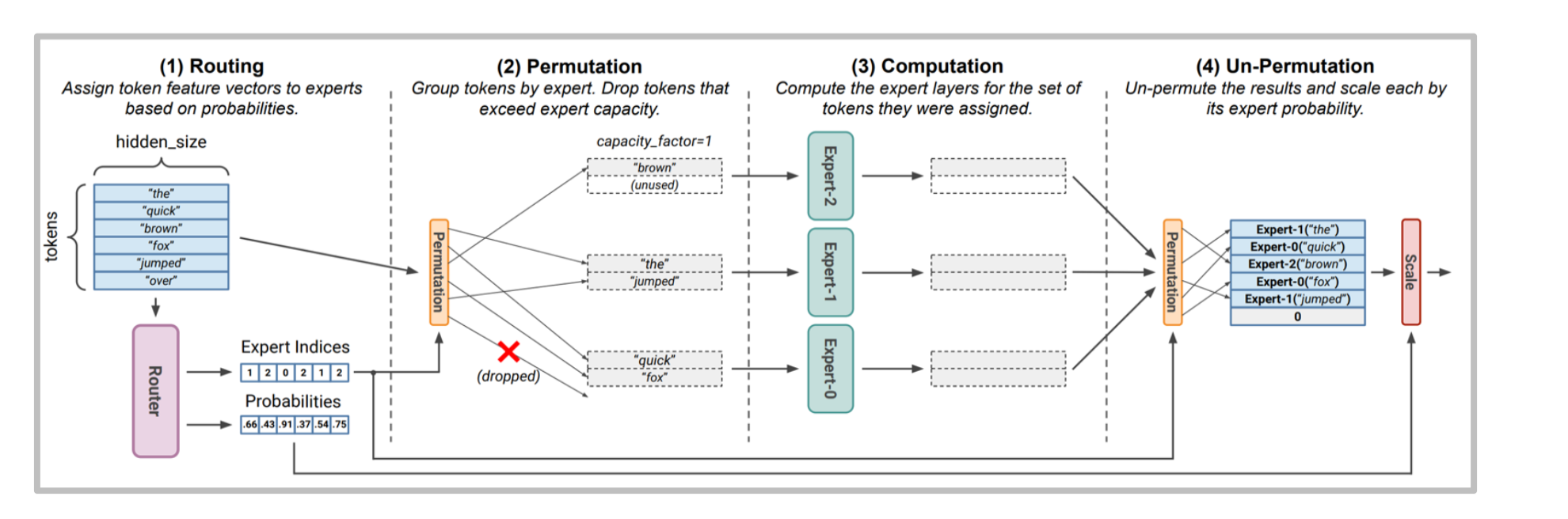
社区曾猜测 GPT-4 的随机性来自 MoE。结合上图,MoE 的非确定性主要来自三处:
- 概率路由:router 为每个 token 生成专家分布,再以 top-k 或采样方式选专家。若引入温度或噪声,路径天然带随机性。
- 容量裁剪:专家有
capacity_factor限制。批内若有太多 token 打到同一专家,超出的 token 会被 drop。注意这是 batch 级别 的裁剪——别人的请求会决定你的 token 是否掉队。drop token 会被“旁路”回主干 FFN(如果实现提供 fallback),否则直接丢弃,对最终 logits 形成扰动。 - 并行调度:专家彼此独立执行,异步完成后再 un-permute 回原序列。设备级别的非确定性(尤其是多机多卡)也会放大输出抖动,甚至因通信顺序不同产生细微的浮点差异。
因此,即便温度设为 0,同样 prompt 仍可能走到不同专家组合,输出出现“隐性随机”。
4. 稳定路由:Float32 + Z-Loss
Zoph 2022 提供的经验做法:仅将路由器计算保留 Float32,并额外加一个 aux z-loss。理由是:
- router logits 对精度极其敏感,FP16/BF16 下的小偏差会被 softmax 放大,导致路由翻转;
- z-loss 可以抑制极端大的 gate logits,减少梯度爆炸。
实现上常用的 z-loss 形式是
\[L_{\text{z-loss}} = \lambda \left(\log \sum_j e^{z_j}\right)^2\]其中 $z_j$ 是 router logits,$\lambda$ 为一个很小(1e-4 量级)的系数。它把 logits 的 log-sum-exp 压回有限区间,让分布更平滑。因为只作用在路由器上,这项开销很低,却显著降低训练初期的发散率,也让推理更可复现。
额外的工程提醒:
- MoE Router 的 softmax 建议使用
float32中间态,即便主模型是 BF16; - 在推理侧保持确定性 All-to-All 顺序,或固定随机种子,也能进一步收敛输出差异。
5. Upcycling:把密集模型“回收”为 MoE
Upcycling 的目标是把已有的 dense checkpoint 直接转成稀疏 MoE,避免从头训练。典型案例:
- MiniCPM MoE:在 MiniCPM 基座上挂 8 个专家(top-2 激活),活跃参数约 4B,用 520B token 继续训练就能超过原模型。
- Qwen MoE:基于 Qwen 1.8B 初始化,扩展为 top-4、60 专家,再配 4 个共享专家,结构类似 DeepSeekMoE,是已公开的 upcycling 成功范例之一。
升级流程的共性套路:
- 复制 dense FFN 权重到各专家,可加少量噪声防止完全同构;
- 初始化 router 为均匀分布,搭配 load balancing loss(例如
aux_loss = mean(sum(p)^2)); - 用少量继续预训练(数百 B token)让 gate 学会分工;
- 在评估确认质量持平后,逐步拉高 capacity、激活稀疏推理路径。
这样做的优势是几乎零成本复用旧 checkpoint,缺点是需要在早期小心防止专家塌缩(所有 token 只走少数专家),因此 upcycling 期常配合专家正则或 periodic noise。
6. DeepSeek 的两大附加武器
DeepSeek-V3 不只在 MoE 上做文章,还引入了 MLA(Multi-head Latent Attention) 与 MTP(Multi-Token Prediction)。二者分别指向“KV 缓存省显存”和“多 token 训练信号”。
6.1 MLA:用 latent 表征压缩 Q/K/V
核心思想:先把隐藏状态压到一个低维 latent,再从 latent 恢复出 Q/K/V。
\(c_t^{KV} = W^{DKV} h_t,\quad k_t^C = W^{UK} c_t^{KV},\quad v_t^C = W^{UV} c_t^{KV}\) \(c_t^{Q} = W^{DQ} h_t,\quad q_t^C = W^{UQ} c_t^{Q}\)
“latent” 指的是比原 d_model 更小的中间空间,用它来存储 KV 缓存:
- 推理节省显存:缓存 $c_t^{KV}$ 的维度显著小于原始 K/V。
- 训练减激活:压缩后的表示让中间激活内存随之下降。
- 权重可折叠:$W^{UK}$ 可并入查询路径,运行时减少一次 matmul。
在工程实现上,MLA 还有两个常见注意事项:
- latent 维度通常选择
d_model / 4或d_model / 8,确保压缩比与注意力质量达到平衡; - 需要对 KV cache 的布局重写,让
c_t^{KV}可以被直接追加、无需再膨胀回全维,降低内存带宽。
RoPE 的兼容性
RoPE 直接作用在 Q/K 上,而 MLA 将 K 拆成 latent→up-proj,使得旋转矩阵无法事先融合。解决办法是在 K 中保留一小段“非 latent”维度,专门用于旋转;余下部分仍走 latent 流程。另一种做法是在 latent 空间插入旋转(先 up-proj、乘 RoPE、再 down-proj),但那会抵消一部分压缩收益,因此 DeepSeek 更倾向于“混合通道”的折衷方案。
6.2 MTP:一次前向预测多个 token
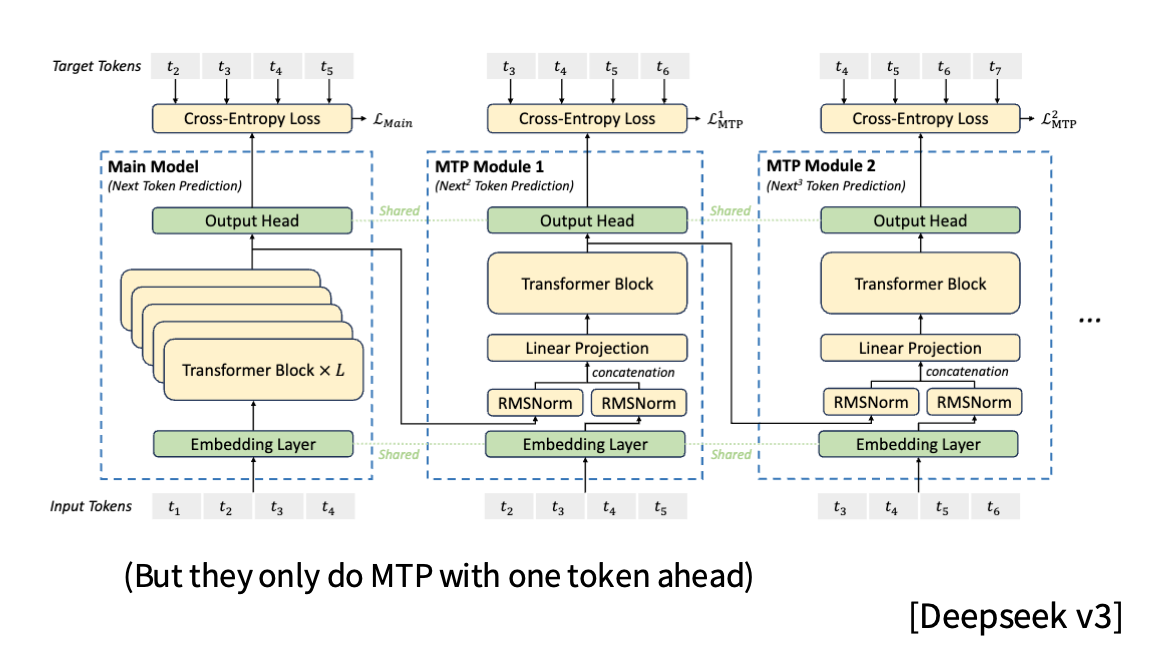
DeepSeek-V3 的 Multi-Token Prediction 在主模型外挂了一串轻量模块,每个模块向前多预测一步:
- 主模型输出 $t_{i+1}$。
- MTP Module 1 用共享 embedding + 轻量 Transformer 预测 $t_{i+2}$。
- MTP Module 2 继续预测 $t_{i+3}$,以此类推。
其内部计算形式:
\(h_i^k = M_k[\text{RMSNorm}(h_i^{k-1}); \text{RMSNorm}(\text{Emb}(t_{i+k}))]\) \(h_{1:T-k}^k = TRM_k(h_{1:T-k}^{k}),\quad P_{i+k+1}^k = OutHead(h_i^k)\)
特点:
- Loss densification:每个位置会收到来自未来多个 token 的交叉熵信号,加快收敛。
- 共享头部:所有模块复用 embedding / output head,只额外增加少量轻量层。
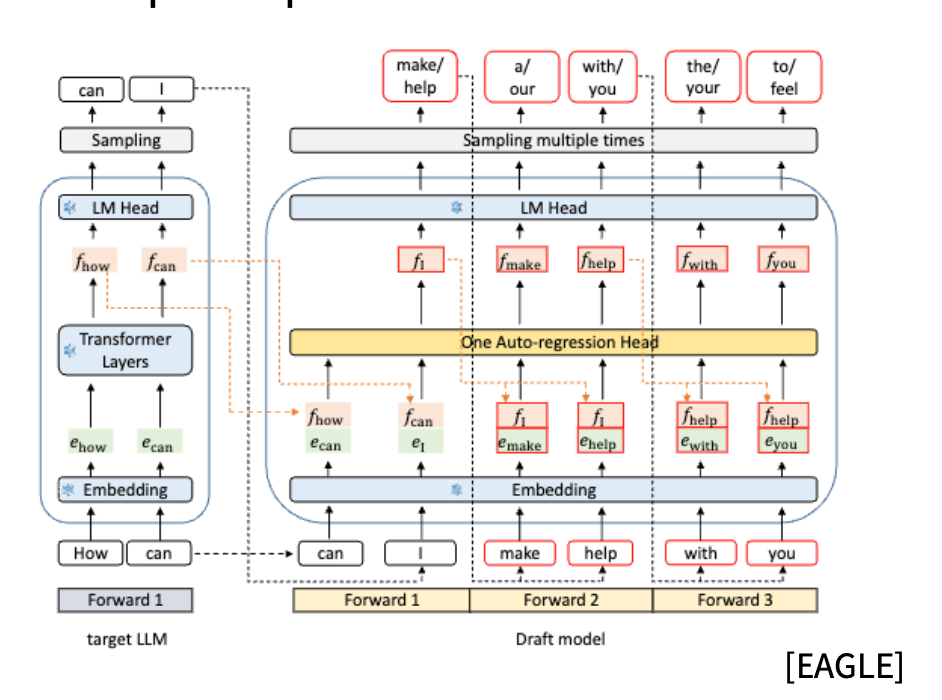
- 推理友好:相较 EAGLE 那种“同一个 LM head 多次前向”,MTP 只需一次 forward,就能为 speculative decoding 提供多个候选。
训练时,MTP Loss 一般按衰减系数加权(例如第 k 个模块乘 γ^k),防止远期预测噪声过大。推理阶段则可把主模型 + MTP 模块联合用作草稿生成器,与 verifier 组成多 token speculative decoding,实测能把 tokens/s 提升 1.5~2 倍。
| 特性 | DeepSeek-V3 MTP | EAGLE |
|---|---|---|
| 预测方式 | 主模型 + 多个轻量模块 | 单模型多次前向 |
| 并行度 | 一次 forward 出多 token | 每个 token 重新运行 |
| 参数 | 共享 embedding/output head | 全部共享 |
| 推理成本 | 低,适合多 token decoding | 高,需额外前向 |
结合前文:MoE 提供稀疏算力,MLA 解决显存瓶颈,MTP 则让每次前向产出更多训练/推理信号。三者协同后才能撑起 DeepSeek 这代模型的效率优势。