NCCL(NVIDIA Collective Communication Library)提供 GPU 间的集合通信 API,所有操作均与 CUDA Stream 绑定,支持 PCIe、NVLink、InfiniBand 等多种互联。
1 Broadcast
从 root rank 广播数据到所有设备。
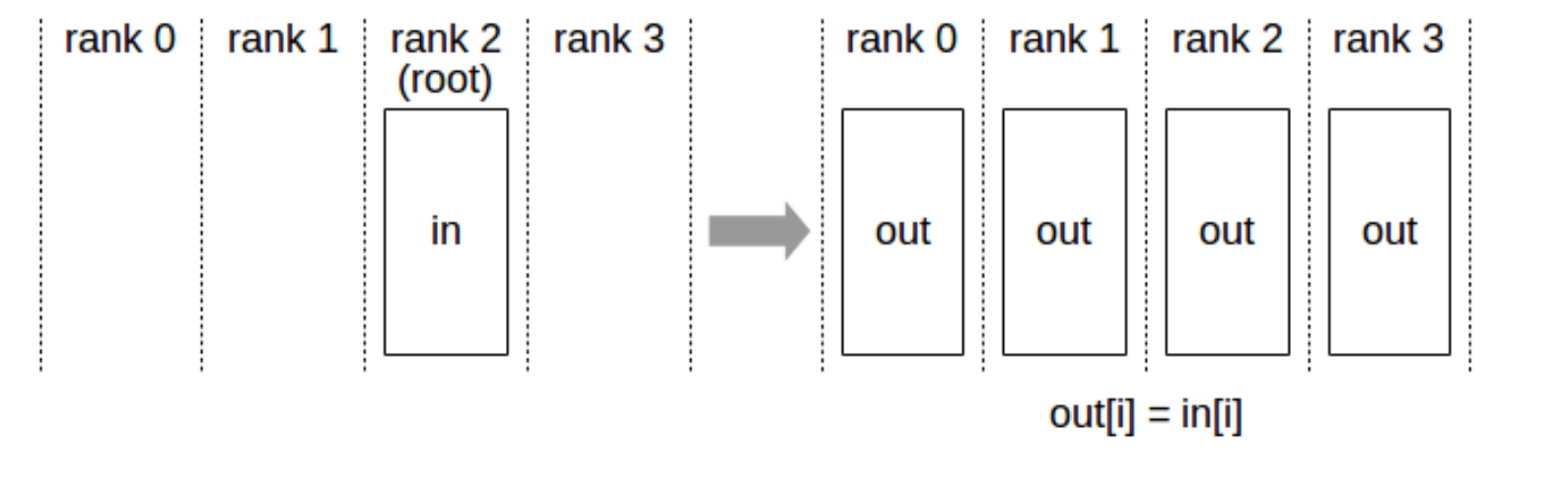
ncclResult_t ncclBroadcast(const void* sendbuff, void* recvbuff,
size_t count, ncclDataType_t datatype,
int root, ncclComm_t comm, cudaStream_t stream)
用途:PP 流水线中广播初始模型权重;DP 初始化时同步参数起点。
2 Reduce
执行规约计算(如 max, min, sum),并将结果写入指定的 rank。
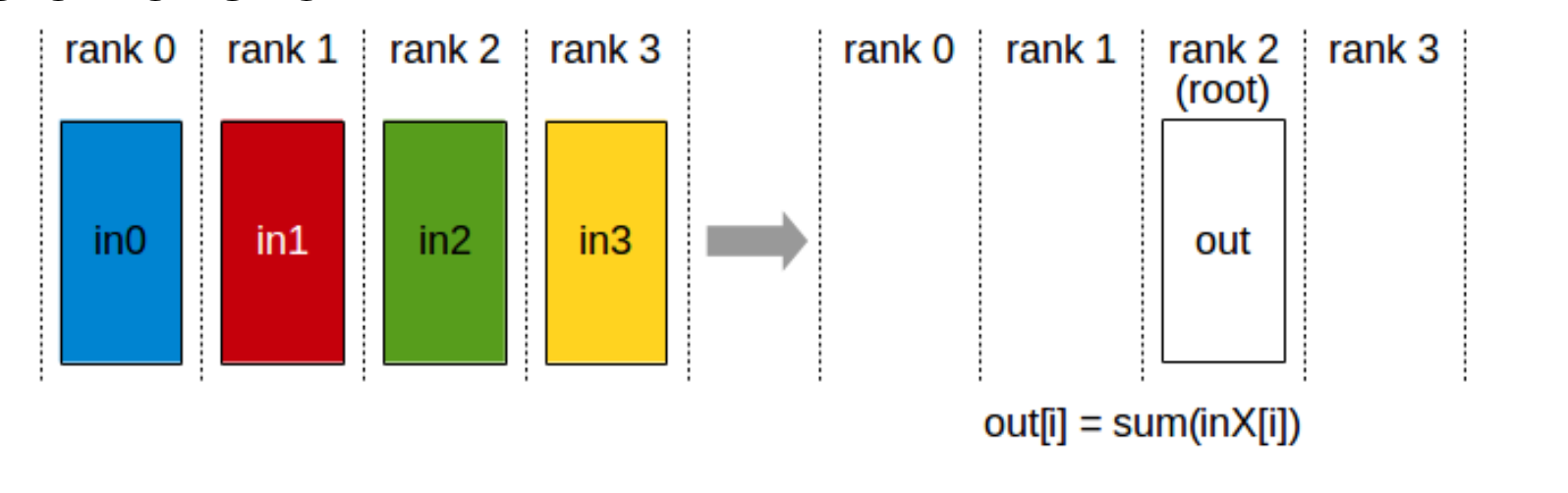
ncclResult_t ncclReduce(const void* sendbuff, void* recvbuff,
size_t count, ncclDataType_t datatype, ncclRedOp_t op,
int root, ncclComm_t comm, cudaStream_t stream)
用途:监控指标(loss、norm)汇总到主进程。
3 ReduceScatter
先对所有 rank 的数据做规约,再将结果按 rank 数量切分后分发,每个 rank 只持有结果的 $1/p$ 份。
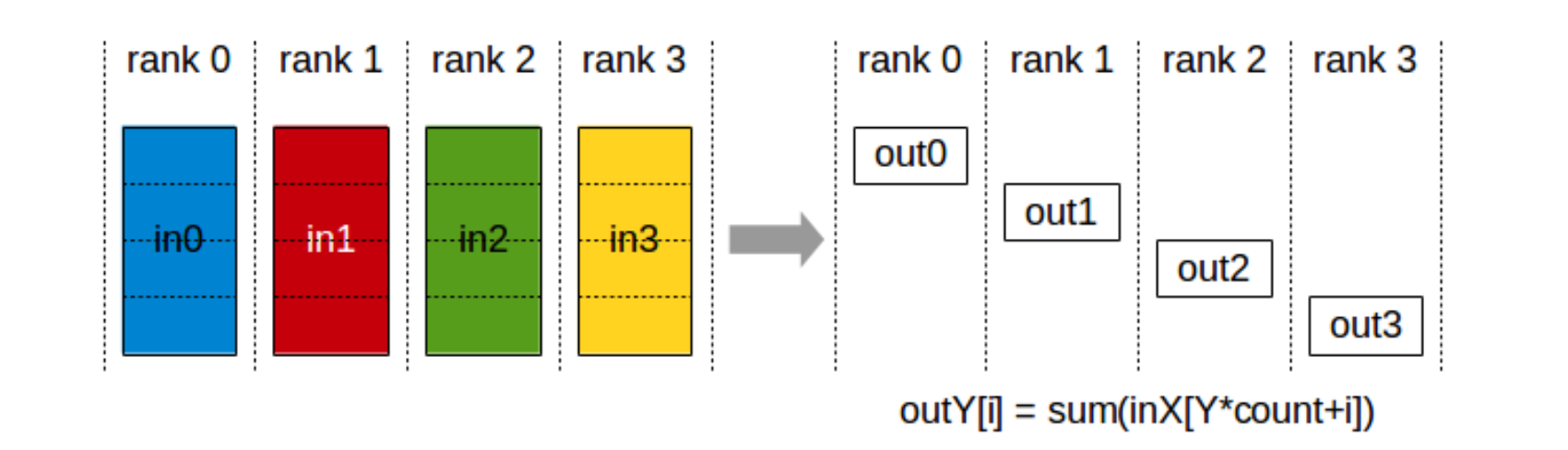
ncclResult_t ncclReduceScatter(const void* sendbuff,
void* recvbuff, size_t recvcount, ncclDataType_t datatype,
ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream)
用途:ZeRO 反向传播时聚合梯度(每卡只保留自己负责的梯度分片);TP + SP 中替代 AllReduce 的后半段。
4 AllGather
每个 rank 贡献自己的 $S/p$ 数据,收集后所有 rank 都持有完整的 $S$ 数据。
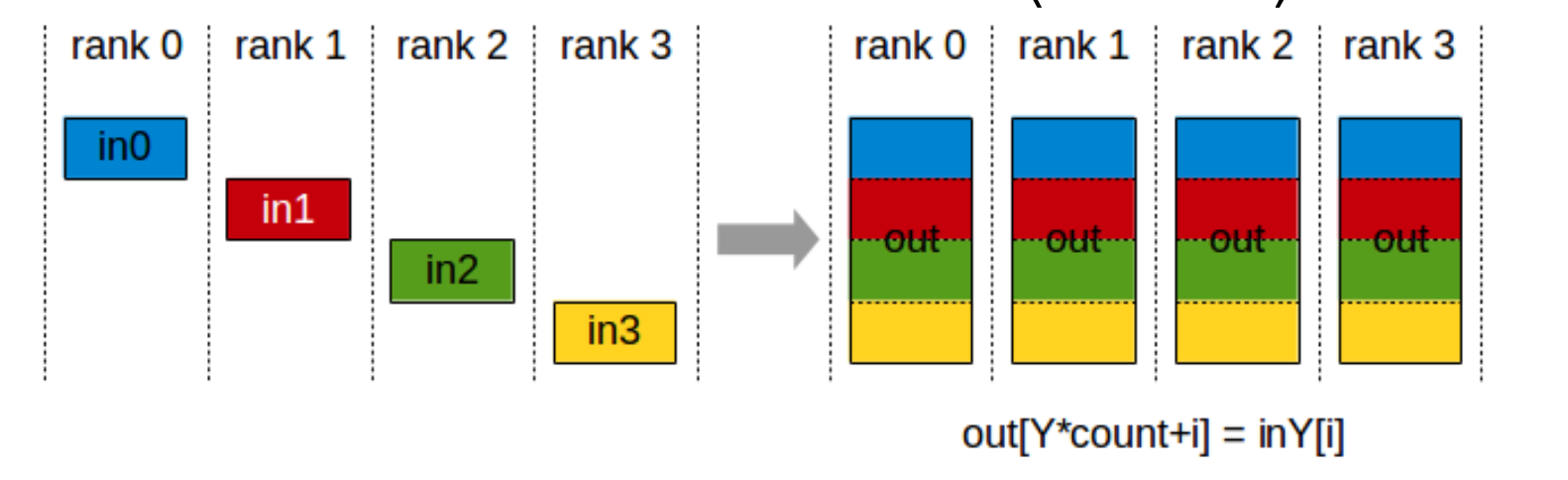
ncclResult_t ncclAllGather(const void* sendbuff,
void* recvbuff, size_t sendcount, ncclDataType_t datatype,
ncclComm_t comm, cudaStream_t stream)
用途:ZeRO 前向传播前重建完整参数;TP + SP 中恢复完整激活。
5 AllReduce
等价于 ReduceScatter + AllGather,规约结果广播到所有 rank。
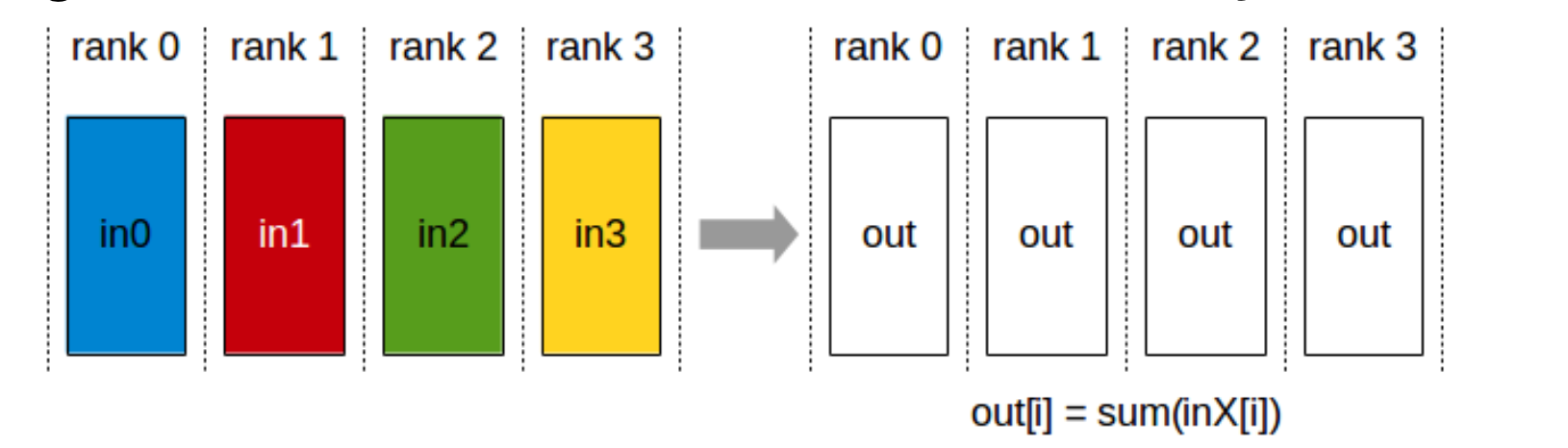
ncclResult_t ncclAllReduce(const void* sendbuff,
void* recvbuff, size_t count, ncclDataType_t datatype,
ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream)
用途:DDP 反向传播后同步所有卡的梯度;TP 中同步每层的激活值。
6 AllToAll
每个 rank 向所有其他 rank 发送不同的数据块,同时接收来自所有 rank 的不同数据块。AllToAll 相当于一次”转置”:发送方维度和接收方维度互换。
发送前(4 卡,每卡持有 [s0,s1,s2,s3]):
GPU0: [a→0, a→1, a→2, a→3]
GPU1: [b→0, b→1, b→2, b→3]
GPU2: [c→0, c→1, c→2, c→3]
GPU3: [d→0, d→1, d→2, d→3]
发送后(每卡收到来自各卡、属于自己的分片):
GPU0: [a→0, b→0, c→0, d→0]
GPU1: [a→1, b→1, c→1, d→1]
GPU2: [a→2, b→2, c→2, d→2]
GPU3: [a→3, b→3, c→3, d→3]
ncclResult_t ncclAllToAll(const void* sendbuff, void* recvbuff,
size_t count, ncclDataType_t datatype,
ncclComm_t comm, cudaStream_t stream)
用途:MoE Expert Parallelism 中,每个 token 根据门控路由到对应的专家所在卡(dispatch),以及专家计算后将结果送回原卡(combine)。
7 原语等价关系
几个重要的等价关系:
\[\text{AllReduce} = \text{ReduceScatter} + \text{AllGather}\] \[\text{AllReduce} = \text{Reduce (to root)} + \text{Broadcast (from root)}\]实际实现中选 ReduceScatter + AllGather 而不是 Reduce + Broadcast,原因见第 8 节。
8 Ring 拓扑实现
8.1 为什么用 Ring
朴素方案(Reduce to root → Broadcast from root)中,root 卡的出入带宽是瓶颈,其他卡闲置。
Ring 方案让所有卡形成一个环,每步每张卡同时发送和接收,所有链路均满负荷,带宽利用率最优。
8.2 Ring ReduceScatter
设 $p=4$ 张卡,每卡持有向量 $[v_0, v_1, v_2, v_3]$(下标表示 chunk 编号),目标是让 GPU$k$ 持有所有卡 chunk $k$ 的总和。
共 $p-1=3$ 步,每步每卡向右邻发送当前负责的 chunk 并累加收到的值:
初始:
GPU0: [a0, a1, a2, a3]
GPU1: [b0, b1, b2, b3]
GPU2: [c0, c1, c2, c3]
GPU3: [d0, d1, d2, d3]
Step 1(GPU0 发 chunk0,GPU1 发 chunk1,以此类推):
GPU0 ← d3; GPU0 持有 [a0, a1, a2, a3+d3]
GPU1 ← a0; GPU1 持有 [a0+b0, b1, b2, b3]
GPU2 ← b1; GPU2 持有 [c0, b1+c1, c2, c3]
GPU3 ← c2; GPU3 持有 [d0, d1, c2+d2, d3]
Step 2:
GPU0 ← c2+d2; GPU0 持有 [a0, a1, a2+c2+d2, a3+d3]
GPU1 ← a3+d3; GPU1 持有 [a0+b0, b1, b2, a3+b3+d3]
GPU2 ← a0+b0; GPU2 持有 [a0+b0+c0, b1+c1, c2, c3]
GPU3 ← b1+c1; GPU3 持有 [d0, b1+c1+d1, c2+d2, d3]
Step 3:
GPU0 ← b1+c1+d1; GPU0 持有 chunk1 = a1+b1+c1+d1 ✓
GPU1 ← a2+c2+d2; GPU1 持有 chunk2 = a2+b2+c2+d2 ✓
GPU2 ← a3+b3+d3; GPU2 持有 chunk3 = a3+b3+c3+d3 ✓
GPU3 ← a0+b0+c0; GPU3 持有 chunk0 = a0+b0+c0+d0 ✓
每卡每步只传输 $S/p$ 的数据,共 $p-1$ 步,每卡总发送量 $(p-1) \cdot S/p$。
8.3 Ring AllGather
ReduceScatter 结束后,GPU$k$ 持有完整规约的 chunk$k$。AllGather 再跑 $p-1$ 步,将每个 chunk 依次沿环传播,最终所有卡都持有完整结果。
总通信量与 ReduceScatter 相同:每卡发送 $(p-1) \cdot S/p$。
9 通信量分析
设数据总大小为 $S$,GPU 数为 $p$,Ring 拓扑下各原语每卡的通信量:
| 原语 | 每卡发送量 | 每卡接收量 | 备注 |
|---|---|---|---|
| Broadcast | $S$(root)/ $0$ | $0$(root)/ $S$ | root 是瓶颈 |
| Reduce | $S$ | $0$(root)/ $S$ | root 是瓶颈 |
| ReduceScatter | $\frac{p-1}{p} S$ | $\frac{p-1}{p} S$ | 带宽均衡 |
| AllGather | $\frac{p-1}{p} S$ | $\frac{p-1}{p} S$ | 带宽均衡 |
| AllReduce (Ring) | $2\frac{p-1}{p} S$ | $2\frac{p-1}{p} S$ | 趋近 $2S$($p$ 大时) |
| AllToAll | $\frac{p-1}{p} S$ | $\frac{p-1}{p} S$ | 类似 AllGather |
Ring AllReduce 的每卡通信量趋近 $2S$,且与 $p$ 无关(相比 Naive 方案的 root 瓶颈有本质改善)。
10 大模型训练中的用途
| 并行策略 | 主要原语 | 时机 |
|---|---|---|
| DDP | AllReduce | 反向传播后梯度同步 |
| ZeRO-1/2 | ReduceScatter | 反向后聚合并分片梯度 |
| ZeRO-3 | ReduceScatter + AllGather | 前向前 AllGather 参数,反向后 ReduceScatter 梯度 |
| TP(无 SP) | AllReduce | MLP/Attention 每层前后 |
| TP + SP | AllGather + ReduceScatter | 序列并行下拆分两步 |
| PP | Send / Recv(P2P) | 微批次在流水线阶段间单向传递 |
| EP(MoE) | AllToAll | dispatch token 到专家,combine 结果回原卡 |