Megatron-LM 引入了一套自研的 FSDP 实现——Megatron-FSDP,替代了之前的custom_fsdp
位于 megatron/core/distributed/fsdp/src/megatron_fsdp/, 可以独立作为一个pip 包独立release
本文从v0.16的源码出发,深入分析它的设计取舍、与 PyTorch FSDP2 的差异、以及它如何与 Megatron m-core 体系深度集成。
v0.16(core_v0.16.1)
一、mFSDP的定位?
PyTorch FSDP2(torch.distributed.fsdp)虽然功能完善,但对 Megatron-LM 的需求存在几个痛点:
- 并行维度耦合:Megatron 同时使用 TP/PP/CP/EP 四种并行。FSDP2 的 module-wrapping 风格难以与
parallel_state管理的 process group 无缝对接。 - Bucket 粒度:Megatron 需要按 FSDP Unit(通常是 TransformerLayer)精细控制参数的释放时机,避免激活重计算(activation recompute)时产生二次 all-gather。
- 通信流水线:Megatron 原有的 DistributedOptimizer 已经有成熟的
reduce_scatter + all_gatheroverlap 机制,Megatron-FSDP 在此基础上演化,而不是从头适配 FSDP2 的 API。 - FP8 支持:TransformerEngine 的 FP8 参数需要管理 transpose cache,FSDP2 对此透明度不够
简单来说就是torch 易用性很好,但是性能一般,拓展性比较差
为什么不直接用 Megatron m-core 的分布式实现?
Megatron m-core 是一套高度优化的建模体系(megatron/core/models/),但对算法研究者来说有几个摩擦点:
- Modeling 侵入性强:m-core 对 Transformer 层结构有强假设(如
TransformerLayer的具体 API、parallel_state的全局状态管理),若要改模型结构——比如换 attention 实现或插入自定义算子——需要在 m-core 内部做”魔改”,维护成本高。 - 与原生 PyTorch 生态脱节:很多算法论文的参考实现直接用
torch.nn.Module+ 标准torch.optim写成。m-core 的接口与这套生态不兼容,移植成本较大。 - Megatron-FSDP 的定位:作为一个独立 pip 包(
megatron-fsdp),它只依赖 PyTorch,可以包装任意torch.nn.Module,不要求模型实现对齐 m-core。这使得在原生 PyTorch 实现的模型上接入 FSDP 和 ZeRO 优化几乎零改动。
本质上,Megatron-FSDP 是把 Megatron 积累的通信优化经验(DistributedOptimizer、overlap 机制、TP 感知分片)提炼成一个框架无关的分布式训练库,而不是绑定在 m-core 的建模体系上。
所以 mfsdp 更像是一种兼容了性能和易用性的存在,介于原生fsdp 和 m-core 之间
二、整体架构
MegatronFSDP(torch.nn.Module 的包装层)
│
├── ParamAndGradBuffer ← 统一管理所有参数/梯度缓冲区
│ ├── ParameterGroup[] ← 按 dtype/expert/requires_grad/fsdp_unit 分组
│ │ ├── model_weight_buffer (BF16/FP8 工作参数;ZeRO-3 下分片)
│ │ ├── main_weight_buffer (FP32 主权重;preserve_fp32_weights=True 时创建)
│ │ ├── main_grad_buffer (梯度缓冲区;ZeRO-2/3 下分片)
│ │ └── hsdp_wbuf/hsdp_gbuf (Hybrid FSDP 专用)
│ └── DataParallelBuffer ← 单个 bucket 的分片缓冲区抽象
│
├── AllGatherPipeline ← 管理参数 all-gather(unshard)流水线
├── GradReducePipeline ← 管理梯度 reduce-scatter 流水线
│
└── Hooks(前/后向钩子)
├── pre_forward: all-gather 当前 FSDP Unit 参数
├── post_forward: 释放(或延迟释放)参数
├── pre_backward: all-gather 参数用于反向传播
└── post_backward: 归还参数、reduce-scatter 梯度
入口函数为 fully_shard_model() / fully_shard()(fully_shard.py):
前者返回 MegatronFSDP 封装后的模型,后者还会原地 patch optimizer,
返回 (MegatronFSDP, optimizer)。
三、分片策略:对应 ZeRO 各级别
Megatron-FSDP 通过 zero_dp_strategy 参数映射到 ZeRO 的四个级别:
zero_dp_strategy |
等价 ZeRO 级别 | 分片内容 |
|---|---|---|
no_shard (0) |
DDP | 不分片,与传统 DDP 等价 |
optim (1) |
ZeRO-1 | 分片优化器状态(+混合精度时的 FP32 权重副本) |
optim_grads (2) |
ZeRO-2 | 分片梯度 + 优化器状态 |
optim_grads_params (3) |
ZeRO-3 / Full FSDP | 分片参数 + 梯度 + 优化器状态 |
默认策略是 optim_grads_params(ZeRO-3),即完全分片。
但要真正获得 FSDP unit 粒度的释放和预取,还需要提供 fsdp_unit_modules;
Megatron 适配层在 optim_grads_params 下默认使用 [TransformerLayer],
四、Per-Module 分片:Megatron-FSDP 与 FSDP2 的核心差异
这是理解 Megatron-FSDP 性能优势最关键的设计点,也是它与 PyTorch FSDP2 最根本的架构区别(出自 NVIDIA PyTorch Conference PPT Slide 11)。
4.1 FSDP2:per-parameter 均匀分片
FSDP2 的分片单位是每个参数(per-parameter):每个参数独立按 DP size 均匀切分,每个 rank 持有大小相等的 shard。
·但问题出在通信时:AllGather/ReduceScatter 需要一块 连续的 per-module collective buffer,而各参数的 shard 分散在各自的内存位置,必须先做 remap_and_copy(permute)将其重排到 (Shard, Param)-Shaped 的通信 buffer 中。这个 permute 步骤在 LM3 405B 训练中带来约 10% 的性能开销。
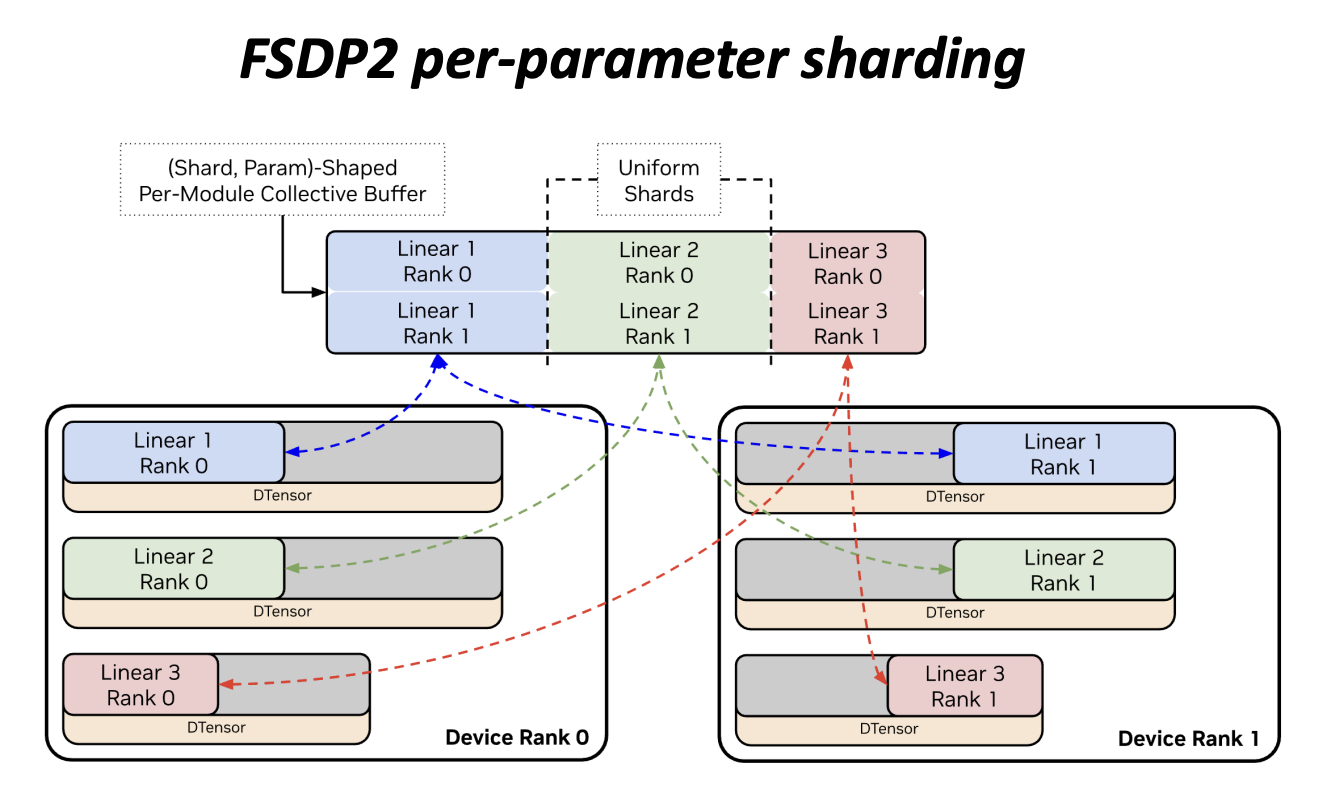
上图(来源:NVIDIA PyTorch Conference)展示了 FSDP2 的 per-parameter 均匀分片:顶部是 (Shard, Param)-Shaped 的 Per-Module Collective Buffer,每行对应一个 DP rank 的 shard,每列对应一个参数;”Uniform Shards”标注表示每个参数在各 rank 上的 shard 大小相等。注意图中箭头是交叉的——Rank 0 上的 Linear 1、Rank 1 上的 Linear 1,来自两个 device,需要先各自切成均匀 shard,再收集、重排到 buffer 同一列,这正是 permute 开销的来源。
4.2 Megatron-FSDP:per-module 非均匀分片
Megatron-FSDP 的分片单位是每个 module(per-module):同一个 FSDP Unit(如 TransformerLayer)内的所有参数拼接成一块连续的 Per-Module Collective Buffer,再按 DP-Shard 数量均匀划分——每个 rank 持有 buffer_size / dp_size 大小的连续切片。
由于参数 shard 与通信 buffer 共享同一块内存,AllGather 的输入就是本地 shard,无需 permute,实现 zero-copy。
代价是:各参数在不同 rank 上的 shard 大小并不相等(Non-Uniform Shards)——这正是 PPT 图示中想说明的:
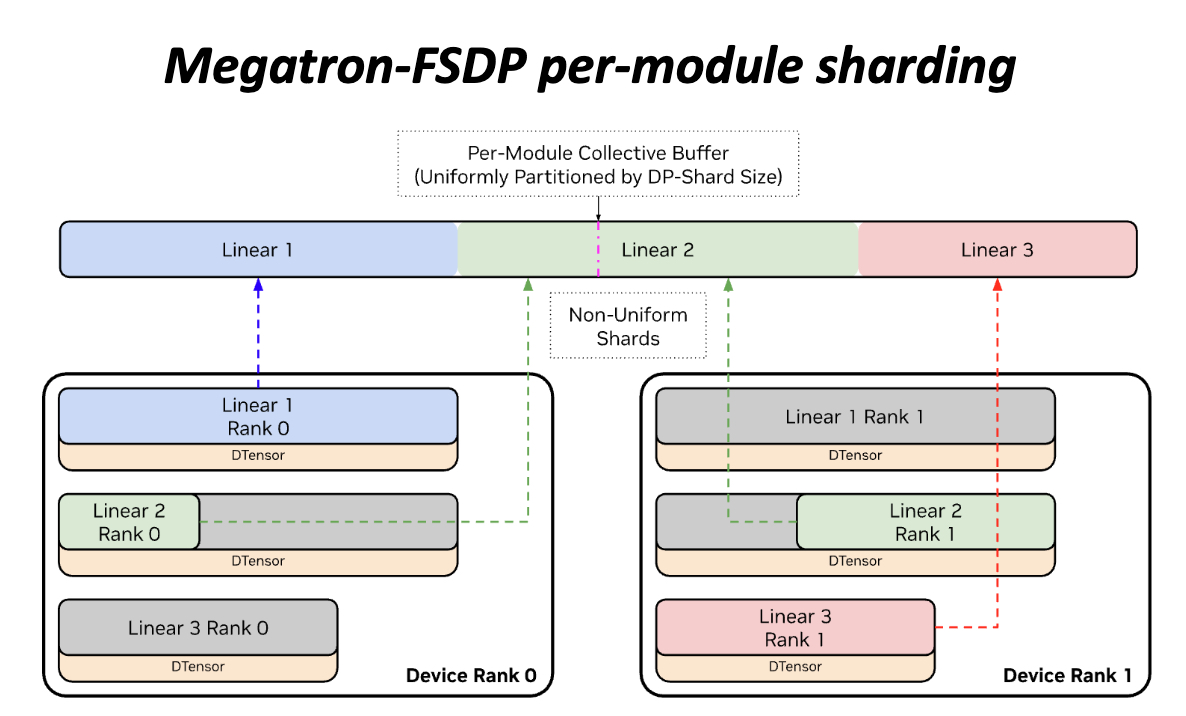
上图(来源:NVIDIA PyTorch Conference)展示了一个含 3 个 Linear 层的 module 在 2 个 rank 上的分片方式:
- 顶部彩色长条:Per-Module Collective Buffer,被 DP-Shard Size 均匀切成两段(Rank 0 / Rank 1 各占一半)
- Device Rank 0:Linear 1 shard 较大(蓝),Linear 2 shard 中等(绿),Linear 3 shard 很小(灰)
- Device Rank 1:Linear 1 shard 较小(灰),Linear 2 shard 中等(绿),Linear 3 shard 较大(粉)
- 箭头:各 rank 的本地 DTensor 直接指向 buffer 中对应位置,无中间拷贝
这种”buffer 均匀、参数 shard 不均”的设计,在与 TP 联合使用时需要保证 FSDP 的分片边界与 TP 分片对齐(见第十三节的 chunk_size_factor 说明),不能被整除时末尾做 padding。
4.3 TP + FSDP 的维度关系
FSDP 分片发生在 TP 切分之后的那份权重上,两者正交:
- TP Column Parallel:
[H, 4H]→ 每个 TP rank 持有[H, 4H/TP] - TP Row Parallel:
[H, 4H]→ 每个 TP rank 持有[H/TP, 4H] - FSDP 分片:把 TP rank 上那份权重展平后按 DP rank 均分(non-uniform shard)
联合使用时,每个 rank 实际持有的参数量为:
rank 持有参数量 ≈ 原始参数量 / TP_size / DP_size
(因 non-uniform sharding 和 padding,各 rank 持有量可能略有差异,但量级相同。)
五、参数分组(ParameterGroup)与 Bucket 划分
5.1 参数分组原则
ParamAndGradBuffer._get_parameter_groups() 把所有参数按以下属性分组:
- dtype:BF16 参数和 FP8 参数不能共享同一个 buffer
- is_expert_param:MoE 的专家参数使用独立的 EP 通信组
- requires_grad:不需要梯度的参数(如冻结层)单独处理
- fsdp_unit_id:属于同一个 FSDP Unit(如同一个 TransformerLayer)的参数分到同一组
5.2 Bucket 大小
BucketingPolicy 类本身的默认 suggested_bucket_size 是 40_000_000
(4000万个元素,BF16 下约 80MB)。但在 Megatron 集成路径里,
实际值来自 ddp_config.bucket_size;如果该值是 None,
非 FSDP unit 参数不会因为 bucket size 被继续切分。
划分逻辑由 _get_parameter_groups() 和 build_data_parallel_buffer_index() 两层完成:
- 先按 dtype、expert、requires_grad、FSDP unit 聚合参数;非 FSDP unit 的参数才会按
suggested_bucket_size继续切 bucket - FSDP unit 内的 bucket 会按
(fsdp_unit_id, is_expert_param)聚合成同一个 collective group,从而减少 NCCL 调用数 - 强制边界:Shared embedding 参数(如词嵌入在 PP pipeline head/tail 复用时)必须独立 bucket
- 最后
build_data_parallel_buffer_index()负责为每个 bucket 生成全局索引、当前 rank 的 shard 索引和必要 padding
5.3 chunk_size_factor
对于 TP 场景,参数实际是 DTensor,需要保证 size % chunk_size_factor == 0 以便 DP ranks 之间平均切分。
chunk_size_factor 来自同一个 bucket 中参数 shape[1:].numel() 的对齐要求:代码先按该值从大到小排序,再在必要时取 LCM。
这样做是为了让 FSDP 的 Shard(0) 和 TP 的切分维度组合时仍能形成合法的 DTensor 分片布局。
如果某个参数不满足对齐要求,会在末尾填 padding,避免”不均匀分片”(uneven sharding)问题
(这也是 uneven_dtensor.py 要解决的 DCP checkpoint 问题)。
六、三套缓冲区:权重、梯度、优化器状态
每个 ParameterGroup 最多会维护以下几个 DataParallelBuffer:
model_weight_buffer → 存放 BF16/FP8 工作参数
(optim/optim_grads 下完整存储,optim_grads_params 下分片)
all-gather 后供前向/反向计算用
transpose_weight_buffer → FP8 专用,存放转置后的参数(columnwise 方向)
main_weight_buffer → 存放 FP32 主权重
(preserve_fp32_weights=True 时才创建)
是优化器真正操作的对象
main_grad_buffer → 存放梯度
reduce-scatter 后的结果积累在这里
(optim_grads/optim_grads_params 策略下是分片的)
hsdp_wbuf / hsdp_gbuf → Hybrid FSDP (HSDP) 专用的参数/梯度 buffer
6.1 训练时数据流
[前向]
model_weight_buffer (BF16/FP8 shard)
→ all-gather → 临时完整参数 bucket
→ 参数 data 指向 bucket 中对应切片
→ 前向计算
[反向]
梯度流到 param.grad (工作精度)
→ _grad_acc: 拷贝到梯度通信 bucket 中对应参数位置
→ reduce-scatter → main_grad_buffer (FP32 shard)
[优化器 step]
main_grad_buffer (FP32 grad shard) + main_weight_buffer (FP32 param shard)
→ optimizer.step() → 更新 main_weight_buffer
[更新模型权重]
install_optimized_model_weights()
→ 把 main_weight_buffer (FP32) cast 回 model_weight_buffer (BF16/FP8)
也就是说,前向/反向使用的是 model_weight_buffer 里的工作精度参数;
main_weight_buffer 是优化器视角的高精度权重。优化器 step 后,
install_optimized_model_weights() 再把主权重写回工作权重。
这套流程借鉴了 Megatron DistributedOptimizer 的 FP32 主权重 + 低精度工作参数模式,
但在 ZeRO-3 下额外管理参数 all-gather / release 生命周期。
七、DataParallelBuffer:分片 Buffer 的核心抽象
DataParallelBuffer 管理单个 bucket 在 DP group 中的分片布局,支持两种模式:
- Sharded 模式(
is_data_distributed=True):每个 rank 只持有一个shard_size = bucket_size / dp_size大小的切片,是真正的分布式存储 - Unsharded 模式(
is_data_distributed=False):每个 rank 持有完整的 bucket,但引入”虚拟分片”(virtual shard)的概念,以便与 sharded buffer 的接口统一
索引系统包含三个层次:
TensorItemIndex # 单个参数在 bucket 内的位置 (global_start, size)
BucketIndex # bucket 的全局信息 (global_start, total_size, items)
ShardBucketIndex # 当前 rank 的 shard 信息 (global_data_index, local_data_index, size)
在 optim_grads_params 模式下:
model_weight_buffer是 Sharded → rank 持有参数切片main_grad_buffer是 Sharded → rank 持有梯度切片main_weight_buffer是 Sharded → rank 持有 FP32 主权重切片
在 optim 模式下:
model_weight_buffer是 Unsharded → 每个 rank 持有完整参数main_weight_buffer是 Sharded → FP32 主权重分片(ZeRO-1 优化器状态分片)
7.1 Non-Uniform Sharding 的代码实现细节
Per-module 非均匀分片的设计原理见第四节。在代码层面,”不均匀”带来两个需要处理的问题:
- 对齐:TP 场景下参数是 DTensor,FSDP 分片边界必须与 TP 的切分维度对齐,否则无法构成合法的 DTensor shard。
chunk_size_factor从参数的shape[1:].numel()推导,保证total_size % chunk_size_factor == 0。 - Padding:若某参数不满足对齐要求,在 bucket 末尾补 padding,避免”不均匀分片”导致 collective 出错。
uneven_dtensor.py 专门处理这类含 padding 的 DTensor 在 Torch DCP checkpoint 中的保存与恢复。
八、All-Gather Pipeline:参数 unshard 的流水线
AllGatherPipeline 管理参数从”分片状态”恢复到”完整状态”的流水线。
8.1 核心机制
# 异步 all-gather 到临时 bucket
ag_pipeline.all_gather_params(
params=param_list,
prefetch=True,
prefetch_order=PrefetchOrder.FORWARD_PASS_ORDER,
suggested_AG_prefetch_size=suggested_AG_prefetch_size,
)
关键设计:
- 独立 CUDA stream:all-gather 在
side_stream_for_param_gather上异步发出,不阻塞计算 stream - Prefetch:在计算当前 FSDP Unit 时,提前 all-gather 下一个 FSDP Unit 的参数
- PrefetchOrder:前向按
FORWARD_PASS_ORDER(模型层顺序),反向按BACKWARD_PASS_ORDER(逆序)
预取大小来自 ddp_config.suggested_communication_unit_size。如果没有显式设置,
代码会根据 FSDP unit 平均参数量或 bucket size 推导,并用 max(1_000_000_000, inferred_size)
给通信 unit size 设置下界,再把
suggested_AG_prefetch_size 设为该值的一半;AllGatherPipeline 自身的兜底默认是
500_000_000 个元素,不是固定的 250MB。
8.2 临时 Buffer 分配器
all-gather 的结果需要临时存储在 GPU 上,直到该 FSDP Unit 完成前向/反向。 为了避免频繁 cudaMalloc,代码里设计了几种分配器:
| 分配器 | 策略 | 适用场景 |
|---|---|---|
TemporaryBucketAllocator |
按 bucket 缓存临时 tensor,free 时删除 | 基础实现 |
StorageResizeBasedBucketAllocator |
复用 tensor 对象,通过 storage resize 释放/恢复显存 | 默认 all-gather 临时 buffer |
RotaryBucketAllocator |
循环复用固定个数的 buffer | 内存碎片较少的场景 |
FixedPoolAllocator |
双缓冲(size=2),FSDP Unit 粒度复用 | fsdp_double_buffer=True 时启用 |
FixedPoolAllocator 的双缓冲策略:
- 找出 bucket 形状和 dtype 相同的一组 FSDP units,并为这些 bucket offset 准备 2 组可复用 global buffer
- 当前 unit 和预取 unit 可以分别占用一组 buffer
- 当 bucket release 后,buffer group 回到 idle pool,供后续 unit 复用
- 对不满足固定池条件的 bucket,会回退到普通临时分配器
8.3 懒释放(Lazy Release)
在激活重计算(activation recomputation / gradient checkpointing)时,
前向 post-hook 并不立即释放参数(lazy=True),
而是把对应 key 标到 bucket_can_be_released。
下一次 async_bucket_gather() 开始时会调用 recycle_unused_buckets(),
把这些已经标记、且不再需要的 bucket 真正释放。
这避免了 activation recompute 刚 gather 完参数又立刻释放,随后 backward 又重复 all-gather。
九、GradReduce Pipeline:梯度 reduce-scatter 的流水线
GradReducePipeline 管理梯度从”本地工作精度 grad”到 main_grad_buffer
的规约过程;当 grad_reduce_in_fp32=True 时,main_grad_buffer 使用 FP32。
9.1 梯度积累(_grad_acc)
每个参数的 backward 结束后,触发 grad accumulation hook:
def _grad_acc(param):
gbuf = group.hsdp_gbuf if group.hsdp_gbuf else group.main_grad_buffer
if not param.grad_added_to_main_grad:
param.main_grad = param.get_main_grad() # 申请/获取 bucket 中的 shard 位置
if param.grad is not None:
param.main_grad.copy_(to_local_if_dtensor(param.grad))
del param.grad
optim_grads_params/optim_grads模式:param.main_grad指向临时完整 bucket 中该参数的位置,随后 reduce-scatter 累加进本地main_grad_buffershardno_shard/optim模式:main_grad_buffer非分片,_grad_acc()对多个 microbatch 做本地累加,最后 all-reduce- HSDP 外层分片时,梯度先写入
hsdp_gbuf,再按外层策略写回更细粒度的main_grad_buffer
9.2 Reduce-Scatter 触发时机
grad_reduce_every_bprop = (sharding_strategy in ["optim_grads", "optim_grads_params"])
if grad_reduce_every_bprop or is_last_microbatch or model_auto_sync:
grad_reduce_pipeline.reduce_gradients(...)
- ZeRO-3/ZeRO-2 (
optim_grads_params/optim_grads):每次反向传播都做 reduce-scatter (每个 microbatch 的完整梯度 bucket 是临时通信输入,reduce-scatter 后只保留本地 shard) - ZeRO-1/DDP (
optim/no_shard):只在最后一个 microbatch 才做 all-reduce (可以在多个 microbatch 间做梯度累积)
9.3 Queue 机制:控制流水线深度
# 等待队列中的旧 reduce-scatter 完成,直到队列长度或总元素量降到阈值
def wait_for_previous_grad_reduce(self, suggested_queue_size=1, suggested_queue_capacity=None):
while queue_too_large:
event, free_grad_bucket, bucket_id = self.grad_reduce_queue.pop(0)
event.wait() # 等待 reduce-scatter 完成
free_grad_bucket() # 释放临时梯度 buffer
双缓冲限制(_enforce_double_buffer_limit)确保同时在途的 reduce-scatter 不超过 2 个 FSDP Unit,
避免显存中同时存在过多临时梯度 buffer。
9.4 梯度拷贝融合(Gradient Copy Fusion)
FSDP2 的梯度处理需要额外一步 remap_and_copy:
FSDP2:compute_weight_gradient(X, dY) → dW
→ remap_and_copy(dW) → reduction buffer ← 额外拷贝!
→ reduce_scatter(reduction buffer)
Megatron-FSDP:_grad_acc() 直接将 param.grad 写入 main_grad_buffer 中对应的
shard 位置(zero-copy),再 reduce-scatter
由于 per-module 的 buffer 布局(见 7.1 节)保证参数 shard 与梯度 buffer 位置直接对应,梯度可以跳过 remap 步骤直接写入通信 buffer。这种”梯度直写”在实测中带来约 2% 的吞吐提升。
十、DP Overlap:通信与计算的 Overlap
Megatron-FSDP 通过两条独立的 CUDA stream 实现 communication-computation overlap:
# 在 MegatronFSDP.__init__ 中初始化
self.side_stream_for_param_gather = torch.cuda.Stream() # AG stream
self.side_stream_for_buffer_copy_and_grad_accum = torch.cuda.Stream() # RS stream
10.1 All-Gather Overlap(前向)
时间轴:
[main stream] compute FSDP_Unit_0 → compute FSDP_Unit_1 → ...
[ag stream] AG(Unit_1) --------→ AG(Unit_2) ----------→ ...
↑ 在计算 Unit_0 时提前 AG Unit_1
overlap_param_gather=True 时启用。
10.2 Reduce-Scatter Overlap(反向)
时间轴:
[main stream] backward Unit_N → backward Unit_{N-1} → ...
[rs stream] RS(grads_N) ----→ RS(grads_{N-1}) ----→ ...
↑ 在计算 Unit_{N-1} 的梯度时异步规约 Unit_N 的梯度
overlap_grad_reduce=True 时启用(ZeRO-2/3 默认开启)。
10.3 微批次间的 Overlap(Gradient Accumulation Overlap)
当 sync_model_each_microbatch=False(推荐的梯度累积模式)时:
microbatch 0: forward → backward → RS(async)
↓ RS 未等待
microbatch 1: forward → backward → RS(async)
↑ RS overlap 进入 compute 的间隙
microbatch N (last): forward → backward → RS(async) → finish_grad_sync()
↑ 统一等待所有 RS 完成
这是性能最高的训练模式,但需要用户正确设置 is_last_microbatch 标志。
如果通过 fully_shard() 这个独立 API 进入,sync_model_each_microbatch 默认是 True;
直接构造 MegatronFSDP 时默认是 False。Megatron-LM 适配层走后者,
再由 pipeline schedule 的 no_sync_func / grad_sync_func 控制同步点。
十一、钩子生命周期:Hook-Based Orchestration
MegatronFSDP 通过注册 PyTorch 前/后向钩子管理参数的分片生命周期。
11.1 状态机
class TrainingState(Enum):
FORWARD # 参数已 unshard,前向计算中
PRE_BACKWARD # 参数已 unshard,反向计算中
POST_BACKWARD # 梯度已产生(implicit,not tracked explicitly)
IDLE # 参数已 shard/释放
11.2 钩子流程(optim_grads_params 模式)
前向传播:
pre_forward_hook (per FSDP Unit)
→ all_gather_and_wait_parameters_ready() # 同步等待 AG 完成
→ 设置 _training_state = FORWARD
[module.forward() 计算]
post_forward_hook (per FSDP Unit)
→ 普通前向:release_module_parameters(lazy=False),并设置 _training_state = IDLE
→ 激活重计算前向:release_module_parameters(lazy=True),延迟释放
root_pre_backward_hook(全局,反向开始前)
→ 设置所有 FSDP Unit 的 _training_state = PRE_BACKWARD
→ 标记 bucket_can_be_released = True
→ 收集 _params_require_handle_grad(所有需要处理梯度的参数)
反向传播:
pre_backward_hook (per FSDP Unit, via grad hook)
→ all_gather_and_wait_parameters_ready(bwd=True) # 反向 AG
[module backward 计算,产生 param.grad]
per_param_grad_hook (per parameter, via AccumulateGrad hook)
→ _grad_acc(param) # 拷贝到 main_grad shard
→ reduce_gradients() if eligible # 异步 RS
post_backward_hook (per FSDP Unit, via RegisterFSDPBackwardFunction)
→ release_module_parameters(bwd=True) # 立即释放参数
→ 设置 _training_state = IDLE
root_post_backward_hook(全局,反向结束后)
→ _grad_acc() for any remaining params # 兜底
→ reduce_gradients() for remaining grads
→ microbatch_count += 1
→ if model_auto_sync: finish_grad_sync() # 同步等待所有 RS 完成
十二、优化器集成:finish_grad_sync() 与 install_optimized_model_weights()
12.1 finish_grad_sync()
在 optimizer.step() 前调用,完成梯度同步:
def finish_grad_sync(self):
# 1. 等待所有异步 reduce-scatter 完成
self.synchronize_gradient_reduce()
# 2. 将 main_grad_buffer 中的梯度附加到 optimizer 参数上
self.attach_grad_to_optimizer_state()
# 3. 若开启参数 gather overlap,清理所有 pending all-gather
if self.ddp_config.overlap_param_gather:
self.synchronize_param_gather()
# 4. 替换模型参数为分布式优化器参数
self._replace_param_with_distributed_if_needed()
# 5. 重置 microbatch 计数器
self.microbatch_count = 0
12.2 install_optimized_model_weights()
在 optimizer.step() 后调用,把更新后的主权重写回工作参数:
def install_optimized_model_weights(self):
# FP32 main_weight_buffer → BF16/FP8 model_weight_buffer
param_and_grad_buffer.copy_main_weights_to_model_weights()
对于 FP8,这里会调用 fp8_quantize() 把 FP32 量化回 FP8,
并通过 all_reduce(amax) 在 DP group 内同步量化范围。
12.3 优化器参数替换
_replace_param_with_distributed_if_needed() 把模型中的原始参数替换为
ParamAndGradBuffer.optimizer_named_parameters 中的分布式参数。
这些参数优先来自 main_weight_buffer;如果没有 FP32 主权重,则回退到
model_weight_buffer 或原始参数。Adam/SGD 等优化器实际操作的是这组分布式参数。
Weight tying(词嵌入权重共享)通过 _reestablish_shared_weights() 在替换后重新建立。
十三、TP + FSDP 联合:Strided Sharding
当同时使用 Tensor Parallel(TP)和 FSDP 时,需要特别处理分片之间的对应关系。
13.1 DeviceMesh 配置
device_mesh = init_device_mesh(
device_type="cuda",
mesh_shape=(dp_size, tp_size),
mesh_dim_names=("dp_cp", "tp"),
)
dist_index = FSDPDistributedIndex(
device_mesh=device_mesh,
dp_shard_dim="dp_cp", # FSDP 在 dp 维度做分片
tp_dim="tp", # TP 维度(必须提供)
)
13.2 DTensor 与 Strided Sharding
Megatron 的 TP 参数是 DTensor,其 placement 标记了参数在 TP 维度的切分方式
(Shard(0) 表示沿第 0 维切,Replicate 表示复制)。
FSDP 在此基础上对 TP 切片做 二次展平分片:
原始权重:[H, 4H]
TP Column Parallel 后(TP=4):
每个 TP rank 持有 [H, H](columns 切分)
FSDP 分片后(DP=8):
每个 rank 持有 H * H / 8 个元素(展平后均分)
→ 该参数在内存中只有 H²/8 个元素
TP 维度的信息通过 get_mcore_tensor_parallel_partition_dim() 获取,
用于计算 chunk_size_factor,保证 FSDP 分片边界与 TP 分片对齐。
13.3 All-Gather 时的 DTensor 处理
All-gather 的输入是 DTensor 的 local tensor(通过 to_local_if_dtensor(p))。
gather 完成后,代码把 DTensor 的 _local_tensor.data 指向临时完整 bucket 中的对应切片;
参数对象仍保留原有 DTensor 外壳和 TP placement,只是 local tensor 变成了可计算的完整 FSDP bucket view。
十四、Hybrid FSDP (HSDP):多级分片
HSDP(Hybrid Sharded Data Parallel)支持”内层全分片 + 外层复制或分片”的混合策略, 适合超大规模集群(如 128 GPU 节点)。
HSDP 拓扑(dp_outer=4, dp_shard=8, TP=1):
┌───────── dp_outer group(4 个节点)──────────┐
│ 节点0: [rank 0~7] (dp_shard group, FSDP) │
│ 节点1: [rank 8~15] (dp_shard group, FSDP) │
│ 节点2: [rank16~23] (dp_shard group, FSDP) │
│ 节点3: [rank24~31] (dp_shard group, FSDP) │
└──────────────────────────────────────────────┘
- inner FSDP(dp_shard_dim):ZeRO-3 全分片,all-gather/reduce-scatter 在 inner FSDP group 内进行
- outer DP(dp_outer_dim):
no_shard:外层仅复制,梯度做 all-reduce(类 DDP)optim:外层也分片优化器状态,梯度 reduce-scatter 到 dp_outer group
HSDP 的通信策略:梯度分片策略下,每个 backward 都会在 inner FSDP group 内 reduce-scatter;
outer group 的梯度通信只在 is_last_microbatch 或 model_auto_sync=True 时触发,
outer_dp_sharding_strategy="no_shard" 时是 all-reduce,"optim" 时是 reduce-scatter。
通过 outer_fsdp_group_grad_reduce 标志控制。
14.1 HSDP 的 4 种集合通信
一个完整的优化步周期内,HSDP 涉及以下 4 种集合通信(按执行顺序):
1. Post-Optim:跨节点(DP-Outer)AllGather 模型参数
→ optimizer.step() 完成后,跨节点 all-gather 最新参数
→ 仅每个优化步触发一次(非每个 micro-batch)
2. Forward Pass:节点内(DP-Shard)AllGather 参数
→ 每次前向前在节点内 all-gather(每个 micro-batch 都执行)
→ 可与计算重叠
3. Backward Pass:节点内(DP-Shard)ReduceScatter 梯度
→ 每次反向后在节点内 reduce-scatter(每个 micro-batch 都执行)
→ 可与计算重叠
4. Pre-Optim:跨节点(DP-Outer)ReduceScatter 梯度
→ 最后一个 micro-batch 反向结束后,跨节点 reduce-scatter
→ 仅每个优化步触发一次
关键性能点:
- 步骤 1、4 的跨节点通信(IB 带宽受限)频率降低到
1/micro-batch 数量 - 步骤 4 的跨节点 RS 可与步骤 3 的节点内 RS 重叠,实测额外带来约 2% 的吞吐提升
十五、NCCL Userbuffer(nccl_ub)优化
nccl_ub=True 时,通信缓冲区通过 ncclMemAlloc 分配并注册到 NCCL:
- 使用 NCCL 的用户缓冲区模式(User Buffer Registration),通过
ncclMemAlloc/memory pool 给通信 operand 提供可注册的稳定显存 - 减少 SM 使用量(NVLink Multicast 下可降至 1–4 SM,IB+SHARP 场景下相比传统 NCCL 也大幅减少),让更多 SM 用于计算
- 必须配合
fsdp_double_buffer=True使用(需要缓冲区地址稳定) - 对 MoE/HSDP/独立 all-gather group 等多通信组场景,会把同一个 memory pool 注册到多个 NCCL group;MCore allocator 使用
MultiGroupMemPoolAllocator,APEX fallback 使用本文代码里的MultiGroupUBRAllocator
十六、与 Megatron 训练循环的集成
mcore_fsdp_adapter.py 中的 FullyShardedDataParallel 是连接 Megatron 训练框架与 MegatronFSDP 的适配层:
class FullyShardedDataParallel(_BaseDataParallel):
def __init__(self, config, ddp_config, module, ...):
# 从 parallel_state 构建 FSDPDistributedIndex
dist_index = self._init_dist_index(pg_collection)
# 根据策略设置默认 FSDP unit 类型
if strategy == "optim_grads_params":
fsdp_unit_modules = [TransformerLayer]
# 包装进 MegatronFSDP
super().__init__(module=MegatronFSDP(...))
# 暴露关键方法给训练循环
finish_grad_sync = self.module.finish_grad_sync
no_sync = self.module.no_sync # 梯度累积 context manager
scale_gradients = self.module.scale_gradients
独立 fully_shard() API 会 patch optimizer,因此 optimizer.step() 可以自动调用
finish_grad_sync() 和 install_optimized_model_weights():
# 前向 + 反向(支持梯度累积)
for i, batch in enumerate(microbatches):
is_last = (i == len(microbatches) - 1)
model.is_last_microbatch = is_last # 或通过 no_sync()/sync() context 间接控制
loss = model(batch)
loss.backward()
# 默认会先 finish_grad_sync(),再执行基础 optimizer.step(),
# 最后 install_optimized_model_weights()
optimizer.step()
# 清零梯度
optimizer.zero_grad(zero_grad_buffer=True)
在 Megatron-LM 训练框架内,FullyShardedDataParallel 与 DistributedOptimizer
进一步集成:schedule 负责在最后一个 microbatch 退出 no_sync() 或调用
grad_sync_func,DistributedOptimizer._copy_main_params_to_model_params() 会在 step
后调用 param_and_grad_buffer.copy_main_weights_to_model_weights()。
十七、性能优化技术与实测数据
以下数据来源于 PyTorch Conference 上 NVIDIA 发布的 Megatron FSDP PPT,测试配置为 LLaMA3 405B 模型。
17.1 各优化技术的性能贡献
| 优化技术 | 性能提升 | 说明 |
|---|---|---|
| Persistent Communication Buffers | ~1.5% | 预分配 double buffer,避免反复 alloc/dealloc,减少显存碎片 |
| NCCL User Buffer Registration | +5–8% | Zero-copy + NVLink Multicast + IB SHARP,降低 SM 占用 |
| Gradient Copy Fusion | ~2% | 梯度直写通信 buffer,省去 remap_and_copy |
| Activation Offload(GB200 C2C) | ~25% | 利用 GB200 的 C2C 带宽将激活值 offload 到 CPU,仅限 GB200 平台 |
| HSDP + Optim Shard(跨节点 RS 重叠) | ~2% | 跨节点梯度 RS 与节点内通信重叠 |
17.2 端到端 Benchmark:LLaMA3 405B,64× GB200
| 配置 | TFLOPS/GPU | 相对基线 |
|---|---|---|
| NeMo: TP4 × PP8 × CP2(DP2) | 1723 | baseline |
| TorchTitan: TP2 × FSDP32(FSDP2) | 1340 | -22% |
| NeMo: TP2 × FSDP32(Megatron-FSDP) | 2020 | +17% |
与 FSDP2 相比,Megatron-FSDP 在相同 TP/FSDP 配置下性能领先约 51%(1340 → 2020 TFLOPS),与传统 TP+PP 基线相比也提升 17%。
17.3 NCCL User Buffer 单项效果
| 平台 | 不开启 UB | 开启 UB | 提升 |
|---|---|---|---|
| 64× B200 | 1589 TFLOPS | 1665 TFLOPS | +5% |
| 64× GB200 | 1875 TFLOPS | 2020 TFLOPS | +8% |
十八、总结:Megatron-FSDP vs PyTorch FSDP2
| 特性 | PyTorch FSDP2 | Megatron-FSDP |
|---|---|---|
| 核心抽象 | FSDPState(per-module 状态) |
ParamAndGradBuffer(全局 buffer 管理) |
| 切分粒度 | per-parameter 均匀切分 | per-module 不均匀切分 |
| Buffer 布局 | (Shard, Param)-Shaped |
按 DP-Shard size 均匀分段 |
| 参数→通信 buffer | 需要 permute/remap(~10% 开销) | Zero-copy 直接映射 |
| 梯度→通信 buffer | 需要 remap_and_copy | 直写(Gradient Copy Fusion,~2% 提升) |
| 参数分组 | 按 FSDP unit 均匀 | 按 dtype/expert/unit 精细分组 |
| Bucket | 无显式 bucket | 有显式 bucket(支持大小/边界控制) |
| 临时 Buffer | 动态分配 | FixedPool 双缓冲复用(~1.5% 提升) |
| 梯度累积 | 通过 no_sync() |
通过 is_last_microbatch / no_sync(),ZeRO-2/3 每步 RS |
| All-Gather 流水线 | 基础 prefetch | 双 stream + 预取大小控制 + PrefetchOrder |
| Reduce-Scatter 队列 | 无 | 容量受控的 queue + 双缓冲限制 |
| TP 集成 | 有限(DTensor 路径) | 原生 Megatron parallel_state 集成 |
| Hybrid FSDP | 支持(HSDP) | 支持,与 Megatron DistOpt 集成 |
| FP8 | 基础 | TE FP8/MXFP8 专门路径,transpose cache 管理;HSDP transpose buffer 仍有限制 |
| NCCL UB | 无 | 支持,MoE 多组注册(+5-8% 提升) |
| ZeRO 级别 | ZeRO-3 | ZeRO-1/2/3 可选 |
Megatron-FSDP 的核心价值在于:在 Megatron-LM 的多维并行体系内, 以最高的通信效率和最细粒度的内存控制实现参数分片, 而不是提供一个通用的 FSDP 框架。 这种专一性使它能够在工程细节上做出 PyTorch FSDP2 难以做到的优化: 双 stream 精细调度、FSDP Unit 粒度的双缓冲、TP 感知的 strided sharding、 以及与 TransformerEngine FP8 的深度集成。