NVL72 是 NVIDIA GB200 系列中一个 72 GPU 的单机级 NVLink 交换网络。它不是简单的 72 张卡互联,而是一个精心设计的 全互连 (full crossbar) + 单级交换 (single switch stage) 拓扑。

硬件构成
整个系统由两个主要部分组成:
计算节点层
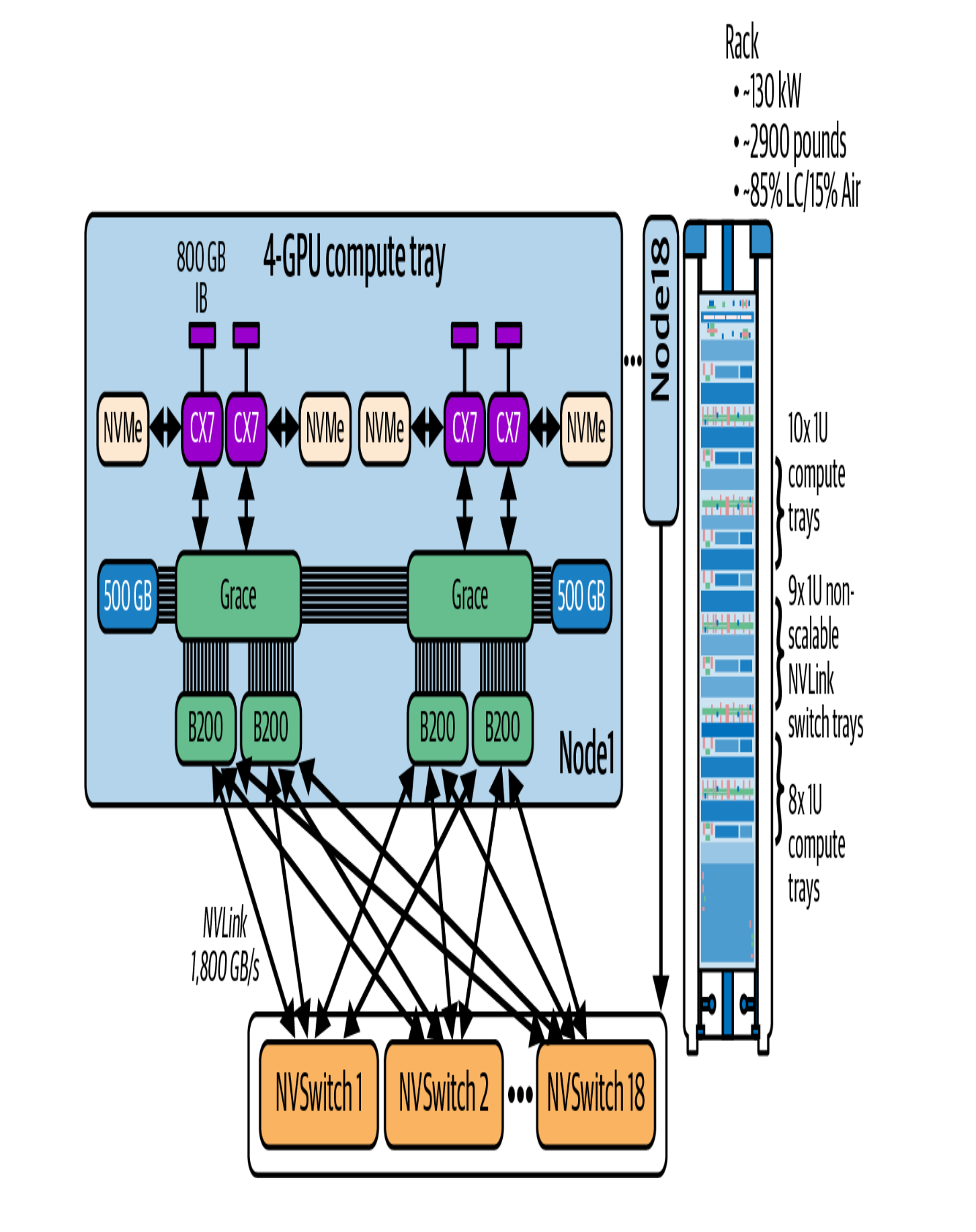
18 个计算托盘 (compute tray),每个托盘包含 4 个 Blackwell GPU,总计:
- 18 × 4 = 72 个 GPU
交换层
9 个 NVLink 交换托盘 (switch tray),每个托盘包含 2 个 NVSwitch 芯片,总计:
- 9 × 2 = 18 个 NVSwitch 芯片
连接拓扑
每个 GPU 的出线
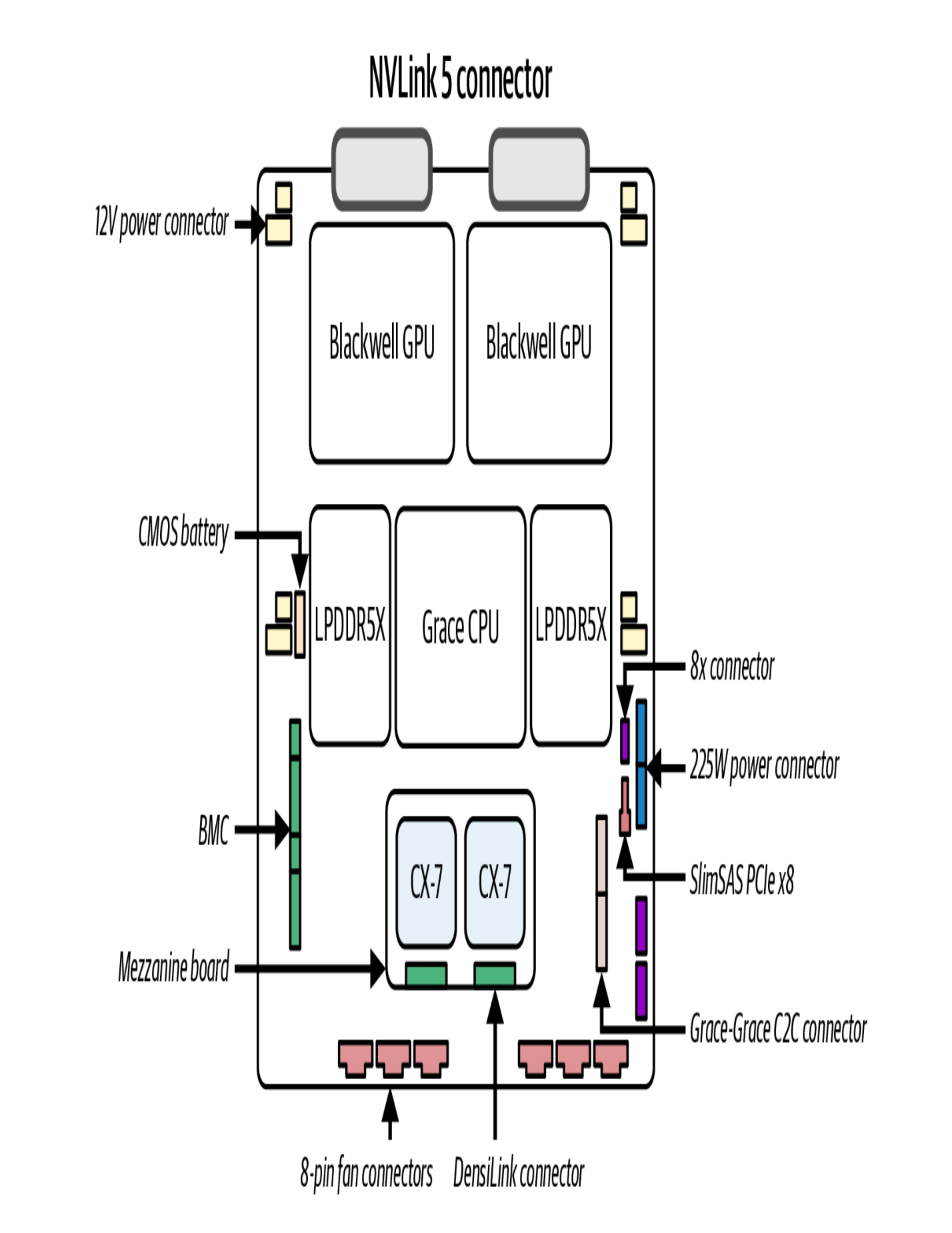
每个 GPU 配备 18 个 NVLink 5 端口,每个端口双向带宽 100 GB/s:
- 单 GPU 总双向带宽:18 × 100 = 1800 GB/s = 1.8 TB/s
关键连接方式
每个 GPU 的 18 条 NVLink,正好一条接一个 NVSwitch。
GPU_i
├─link1 → NVSwitch1
├─link2 → NVSwitch2
├─...
└─link18 → NVSwitch18
这种设计形成一个 full crossbar 结构:
- 每个 GPU 都连到全部 18 个 NVSwitch
- 每个 NVSwitch 也连到全部 GPU 的一部分端口
通信路径
任意两张 GPU 通信时,路径非常简单:
GPU A → 某个 NVSwitch → GPU B
这就是所谓的 single hop / one switch stage。
全二分带宽 (Full Bisection Bandwidth)
这个概念不是”永远不会堵”,而是:
- 如果把整个 72 GPU 网络切成两半
- 两半之间的总连通带宽设计上足够大
- 在均衡流量下,不需要因为拓扑本身而降速或绕远路
它不是一棵容易拥塞的树,也不是分层 oversubscribe 网络,而是尽量做成”任意到任意都能直接经一个交换级过去”的结构。
性能特点
优势场景
- 均衡 all-to-all:性能很好,接近理想状态
- 任意 GPU 到任意 GPU 的路径形式规整
- NCCL 做 collective 时更容易获得高带宽
- 对训练和推理的大规模并行更友好
局限性
- many-to-one / hotspot:仍会遇到拥塞
- 原因不是”路不通”,而是某个目标 GPU 的 ingress 带宽或某个 switch 的吞吐上限被打满
实际应用考量
虽然高层上是”uniform connectivity”,但实际调度时仍需注意:
- 同托盘 / 同板的 GPU,路径更直接、延迟更低
- 某些 collective 算法会把少数链路压得很重
- 拓扑感知调度、NCCL 算法选择、链路 telemetry 都很重要
延迟与带宽对比
在单个 NVL72 机架内:
- GPU 到 GPU 带宽:高达每 GPU 1.8 TB/s(双向聚合)
- 延迟:对于 KB 级别的小消息,延迟约 1-2 微秒
- 大消息耗时更长,通常受带宽限制
相比之下,传统 InfiniBand 网络:
- 带宽:每 GPU 约 20-80 GB/s(取决于网卡数量和速度)
- 延迟:约 5-10 微秒或更高
这种,之前需要跨机器做 规约通信的场景,优势会更显著