本文是《GPU加速策略》的下篇,聚焦内存访问局部性、稀疏矩阵乘法与 cuBLAS 库。上篇讲 CUDA 内存模型与 Tiled 矩阵乘法,见 gpu-acceleration。
7 内存并行与访问局部性
Locality / Bursts Organization 局部排布/交错排除 • Consecutive memory 顺序读取 accesses in a warp are coalesced together. • Row-major format to store multidimensional array in C and CUDA • allows DRAM burst, faster than individual acces
7.1 合并访问 (Coalesced Access)
定义: Warp内连续的内存访问会被合并成单次事务
7.1.1 什么是Warp
- 32个线程为一组,同时执行相同指令
- GPU调度的基本单位
7.1.2 合并访问示例
// 好模式 - Coalesced
int idx = threadIdx.x;
float val = data[idx]; // Thread 0访问data[0], Thread 1访问data[1]...
结果:
- 32个线程访问连续的32个元素
- GPU合并成1次内存事务(128字节)
- 高效!
// 坏模式 - Non-coalesced
int idx = threadIdx.x * 32;
float val = data[idx]; // Thread 0访问data[0], Thread 1访问data[32]...
结果:
- 32个线程访问分散的位置
- GPU需要32次独立内存事务
- 慢32倍!
7.2 行主序 (Row-Major Format)
7.2.1 C/CUDA的多维数组存储方式
float A[4][3]; // 4行3列
内存布局(行主序):
[A00 A01 A02 | A10 A11 A12 | A20 A21 A22 | A30 A31 A32]
←-- Row 0 --→ ←-- Row 1 --→ ←-- Row 2 --→ ←-- Row 3 --→
关键: 同一行的元素在内存中连续存储
7.2.2 访问模式的影响
高效访问(按行)
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
// Warp内线程访问同一行的连续元素
float val = A[row * N + col];
// Thread 0: A[row][0]
// Thread 1: A[row][1]
// Thread 2: A[row][2] 连续!
低效访问(按列)
// Warp内线程访问同一列的元素
float val = A[col * N + row];
// Thread 0: A[0][col]
// Thread 1: A[1][col]
// Thread 2: A[2][col] 跨行访问,不连续!
7.3 DRAM 突发模式 (Burst Access)
7.3.1 什么是DRAM Burst?**
现代DRAM设计为批量传输数据更高效:
单次访问:
- 请求1个字节 → 传输1个字节
- 延迟高 (~500 cycles)
突发访问:
- 请求连续128字节 → 一次性传输128字节
- 延迟仍是 ~500 cycles
- 但吞吐量提升128倍!
7.3.2 为什么突发访问快?
┌─────────────────────────────────────┐
│ DRAM Bank │
│ [连续数据块: 128 bytes] │
│ 一次激活传输整块 │
└─────────────────────────────────────┘
vs.
┌─────────────────────────────────────┐
│ DRAM Bank │
│ [分散访问需要多次激活] │
│ 每次激活开销相同 │
└─────────────────────────────────────┘
7.4 实际应用示例
Tiled矩阵乘法中的合并访问
// 加载A到共享内存(行主序访问)
As[threadIdx.y][threadIdx.x] =
d_A[row * N + ph * TILE_WIDTH + threadIdx.x];
// ↑ row固定 ↑ threadIdx.x连续变化
// Warp内线程访问连续地址!
// 加载B到共享内存
Bs[threadIdx.y][threadIdx.x] =
d_B[(ph * TILE_WIDTH + threadIdx.y) * N + col];
// ↑ threadIdx.y变化 ↑ col固定
// 跨步访问 - 但只加载一次!
8 稀疏矩阵乘法 (Sparse Matrix Multiplication)
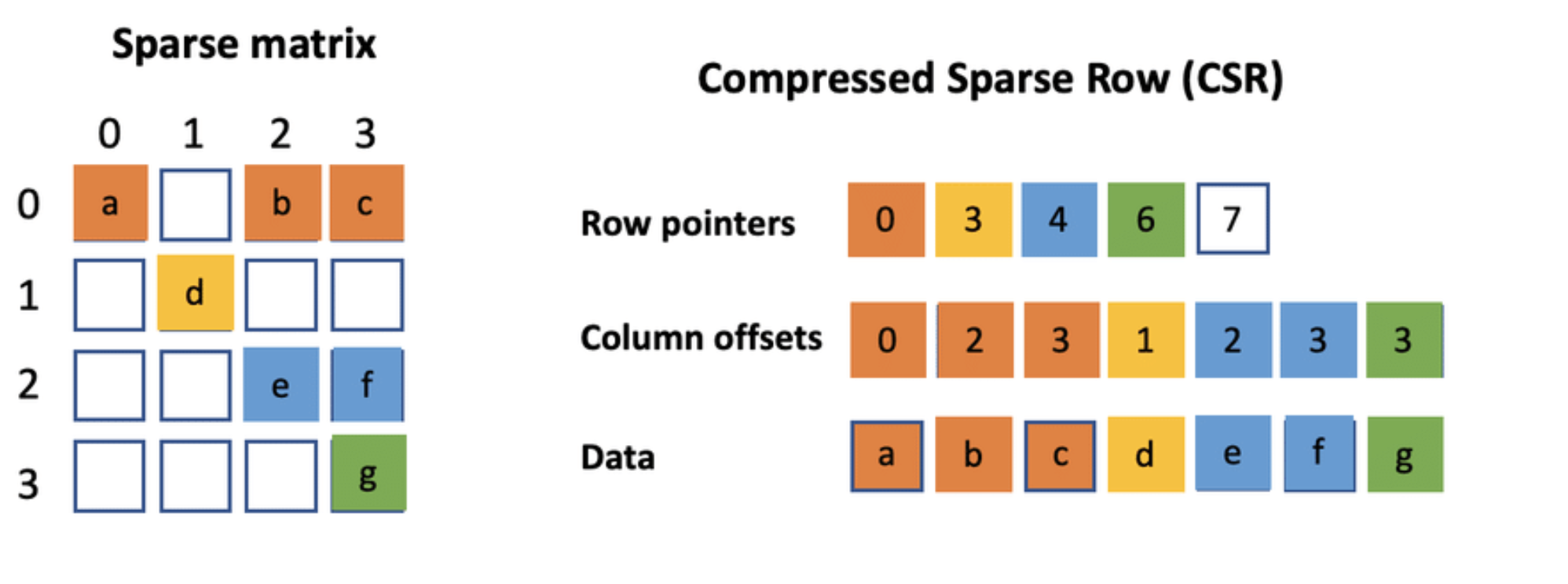
8.1 CSR 格式
- Compressed Sparse Row (CSR):仅存储非零元素
-
三个数组:
data[]:非零元素col_index[]:列索引row_ptr[]:行边界
8.2 代码实现
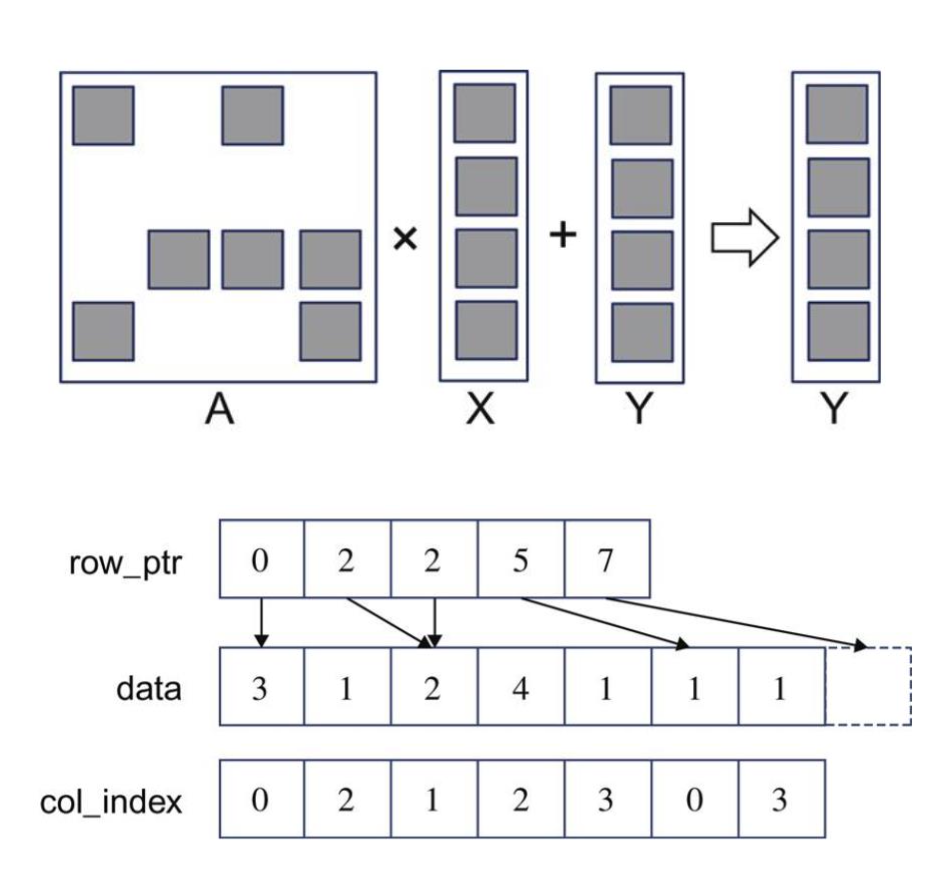
稀松 Sparse Matrix-Vector Multiplication
伪代码:
for(int row = 0; row < n; row++) {
float dot = 0;
int row_start = row_ptr[row];
int row_end = row_ptr[row + 1];
for(int el = row_start; el < row_end; el++)
{
dot += x[el] * data[col_index[el]];
}
y[row] += dot;
}
GPU 实现:
__global__ void SpMVCSRKernel(float *data, int *col_index, int *row_ptr, float *x, float *y, int
num_rows) {
int row = blockIdx.x * blockDim.x + threadIdx.x;
if(row < num_rows) {
float dot = 0;
int row_start = row_ptr[row];
int row_end = row_ptr[row + 1];
for(int elem = row_start; elem < row_end; elem++) {
dot += x[row] * data[col_index[elem]];
}
y[row] += dot;
}
}
9 cuBLAS 库使用简介
Subroutine)** 是用于 矩阵与向量运算 (GEMM) 的高性能库。
\[C = \alpha A \times B + \beta C\]a lightweight library dedicated to GEneral Matrix-to-matrix Multiply (GEMM)
的核心用途是执行 GEMM 运算: GEMM = GEneral Matrix to Matrix Multiply,即 通用矩阵乘法
9.2 常用 API
9.2.1 初始化与销毁
• must call before:
cublasStatus_t cublasCreate(cublasHandle_t *handle)
• must call after:
cublasStatus_t cublasDestroy(cublasHandle_t handle)
9.2.2 向量点积
• float vector dot product
cublasStatus_t cublasSdot (cublasHandle_t handle, int n,
const float *x, int incx,
const float *y, int incy,
float *result)
9.2.3 矩阵向量乘法
\(y = \alpha A x + \beta y\)
cublasStatus_t cublasSgemv(cublasHandle_t handle,
cublasOperation_t trans,
int m, int n,
const float *alpha,
const float *A, int lda,
const float *x, int incx,
const float *beta,
float *y, int incy)
9.2.4 矩阵乘法
\[C = \alpha A B + \beta C\]cublasStatus_t cublasSgemm(cublasHandle_t handle,
cublasOperation_t transa,
cublasOperation_t transb,
int m, int n, int k, const float *alpha,
const float *A, int lda,
const float *B, int ldb,
const float *beta,
float *C, int ldc)
参考代码: llmsys_code_examples/cuda_acceleration_demo/matmul_tile_full.cu