本文是《Transformer 加速策略》的下篇,聚焦混合精度训练与自注意力反向传播的显存复用。上篇讲算子融合与减少同步,见 transformer-acc。
4 混合精度策略
4.1 动机
- 现代 GPU 支持 FP16/FP8(H100)。
- 收益
- 可以减少显存,增大batch size
- 可以更快传输数据
- 可以有更高的FLOPS
4.2 混合策略(为什么不全部采用低精度)
-
forward 和 backward 可以用fp16 /fp8
-
优化器必须用fp32
- FP16 / FP8 的动态范围有限,不能精确地累计很多次梯度更新,会导致数值不稳定、训练不收敛
- 例如: FP16 的最小可表示数约为 6e-8,梯度如果非常小,可能在累计时就变成 0
NVIDIA APEX 库提供自动混合精度(AMP)支持
-
自动把模型的计算分为 FP16 与 FP32 区域。
-
自动管理 loss scaling(避免梯度下溢)。
-
针对常见算子(如 Conv、GEMM、LayerNorm 等)做混合精度优化。
-
使用方式简单,一般只需包一层 amp.initialize(model, optimizer) 即可。
-
这大大简化了混合精度训练的实现复杂度,不用手工改每一层的精度类型
但对超大 LLM 的细粒度显存优化仍需工程化改造
4.3 混合精度的加速
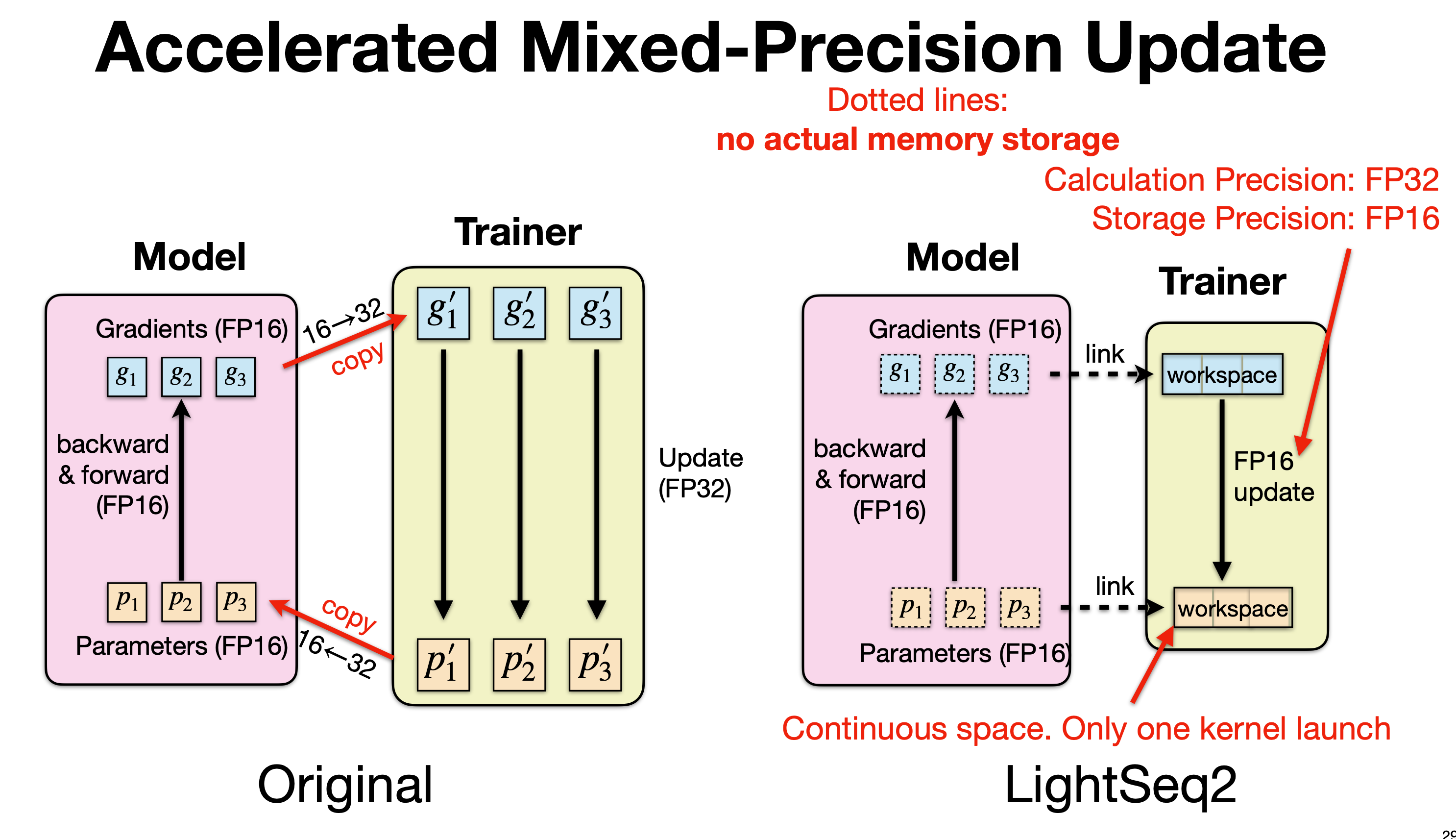
这张图是在讲 混合精度更新(Mixed-Precision Update) 的两种实现方式: 左边是 原始/传统 AMP 实现,右边是 LightSeq2 的加速实现。核心区别在于梯度与参数在 FP16↔FP32 之间的处理方式,LightSeq2 通过消除不必要的内存拷贝与 kernel 启动开销来显著提速。
4.3.1 优化前
常规的混合精度训练流程(比如 NVIDIA APEX AMP):
1. FP16 前后向计算
- 模型参数 ( p_1, p_2, p_3 ) 存储在 FP16 中。
- 前向(forward)和反向(backward)都使用 FP16 精度,计算得到 FP16 的梯度 ( g_1, g_2, g_3 )
2. FP16 → FP32 拷贝
-
在执行梯度更新之前:
- 梯度会被从 FP16 拷贝并转换成 FP32,得到 ( g’_1, g’_2, g’_3 )。
- 参数也会从 FP16 拷贝并转换成 FP32,得到 master 参数 ( p’_1, p’_2, p’_3 )。
这个转换是必要的,因为:
- 优化器(Adam / SGD)更新需要 FP32 的数值稳定性。
- 通常梯度很小,如果不转 FP32,累积时会下溢。
3. Trainer 中的 FP32 更新
- 所有更新(例如 Adam 算法)都在 FP32 空间进行。
- 更新完之后,再把 FP32 参数 cast 回 FP16,传回模型用于下一轮前向。
4. 开销问题
-
每次迭代都要进行:
- 梯度从 FP16→FP32 的 拷贝 + 转换
- 参数从 FP16→FP32 的 拷贝 + 转换
- 每个参数 tensor 需要分别调用 kernel 进行拷贝,kernel launch 次数多。
- 对于 LLM(上百亿参数),这种频繁的转换会成为 显著的性能瓶颈,尤其是在梯度更新步骤。
4.3.2 LightSeq2 优化实现
优化重点是——避免多次内存拷贝 + 合并 kernel 调用,实现加速
1. 梯度和参数依然存储为 FP16
- 计算(forward/backward)依旧在 FP16 上完成。
- 但关键是:梯度和参数不会再被分别拷贝出来存 FP32 的副本。
2. Workspace + 链接(link)机制
图中右侧 Trainer 部分的「workspace」是一个连续的内存块,用于直接处理更新:
-
梯度和参数的 FP16 数据 与 workspace 之间是 link(虚线):
- 表示不进行实际的内存复制(no actual memory storage)。
- 通过指针链接,Trainer 直接访问 Model 的 FP16 数据位置。
-
Trainer 使用一个 连续的 workspace 存储更新所需的中间信息,而不是为每个参数单独分配一段空间
3. FP16 update 内核
-
LightSeq2 使用一个特殊的 kernel,直接在 FP16 上完成参数更新:
- 例如 fused kernel:在一次 kernel launch 里,完成 FP16 → FP32(在寄存器中)、FP32 计算、再 cast 回 FP16。
- 不需要真正拷贝大块参数到 FP32 buffer。
-
这种方式把原来多次 kernel 调用 + 多次内存拷贝,合并成一次连续操作:
- “Continuous space. Only one kernel launch”
4.3.3 优化对比
| 项目 | Original | LightSeq2 |
|---|---|---|
| 梯度/参数转换 | 需要 FP16→FP32 显存拷贝 | 无拷贝,仅链接 |
| 内存使用 | 多个 buffer,分散 | 一个 workspace,连续 |
| kernel 调用 | 多次,小粒度 | 一次,大粒度 |
| 性能瓶颈 | 拷贝 + kernel launch overhead | 极大减少 |
这种优化对于大模型训练(例如数十亿参数)尤其重要:
- 梯度更新步骤的显存带宽占用和 kernel launch overhead 明显降低。
- 更新速度提升,有时能达到 10~20% 的 step time 优化。
5 自注意力反向显存复用
(Memory Reuse GPU Memory Management for Self Attention Backward)
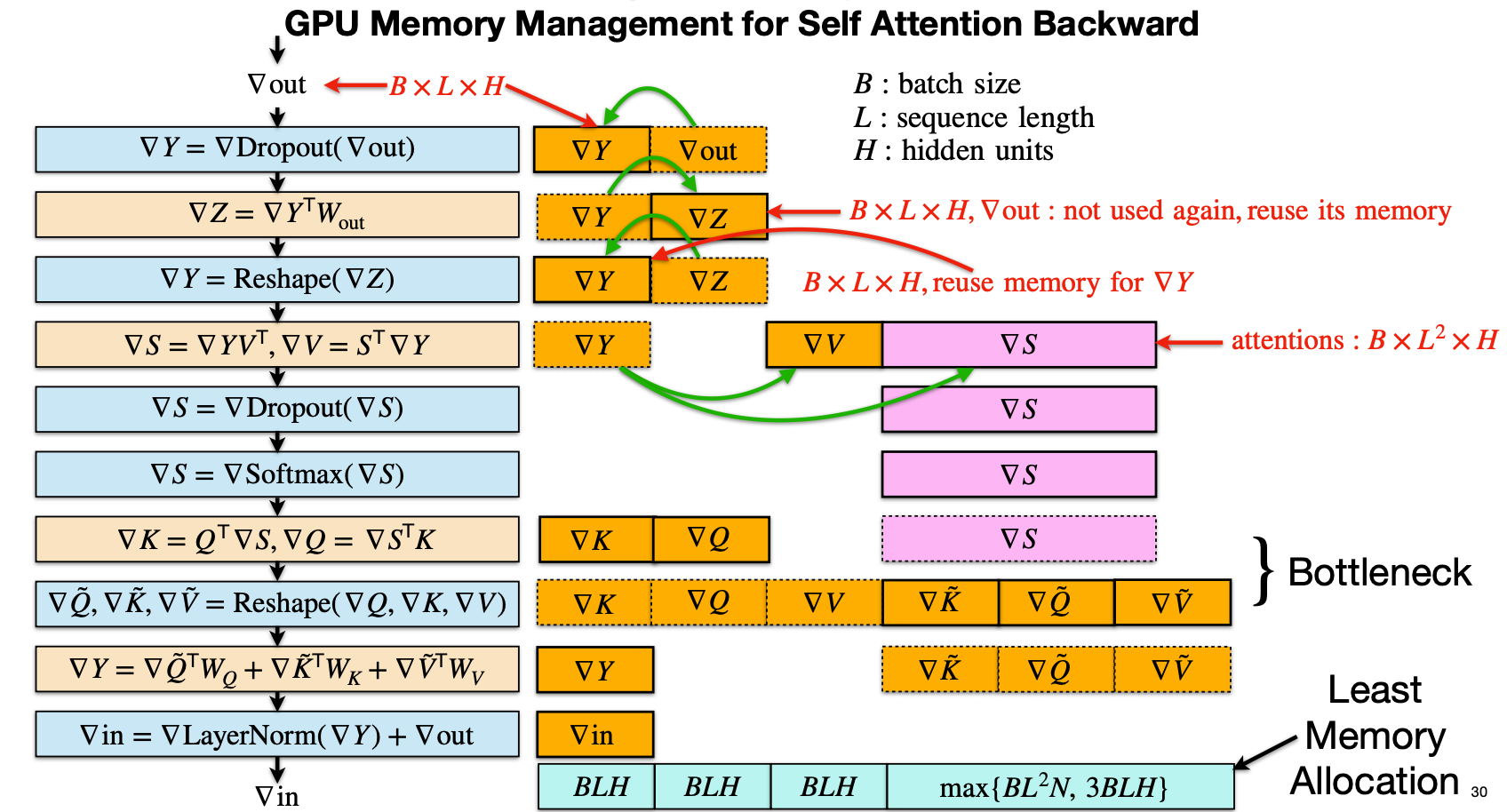
对Transformer 自注意力(Self Attention)反向传播阶段的显存优化方法,通过内存复用(Memory Reuse)来显著降低中间梯度张量的显存占用,从而提升大模型训练的效率。
5.1 反向传播中各个张量的内存开销
图左侧的蓝色和黄色模块展示了自注意力反向传播的标准计算流程,从输出梯度 ( $nabla V_{\text{out}} $ 开始,逐步反向计算各个梯度 主要张量的形状如下:
- $ B $:batch size
- $ L $:序列长度
- $ H $:隐藏维度(hidden size)
| 张量名称 | 尺寸复杂度 |
|---|---|
| $ \nabla V_{\text{out}} $、$ \nabla Y $、$ \nabla Z $ | $ B \times L \times H $ |
| $ \nabla S $(注意力矩阵梯度) | $ B \times L^2 \times H $(或更准确地说是 $ B \times \text{heads} \times L \times L )$ |
| $ \nabla Q, \nabla K, \nabla V $ | $ B \times L \times H $ |
其中 $ \nabla S $ 是最大开销项,因为它对应于注意力矩阵,大小随 ( L^2 ) 增长,是主要显存瓶颈。
5.2 内存复用策略
图中橙色和绿色箭头标出了哪些中间张量可以被回收再利用:
-
复用 $\nabla V_{\text{out}}$ 的内存来存 $\nabla Y$
- 在 Dropout、W_out 反向计算之后,$\nabla V_{\text{out}}$ 不再被使用
- 它的内存大小为 $B \times L \times H$,可以直接复用这块空间来存 $\nabla Y$
-
复用 $\nabla Z$ 的内存来存后续的 $\nabla Y$
- 计算 $\nabla Z = \nabla Y^\top W_{out}$ 后,$\nabla Z$ 也不再需要
- 可以将这块 $B \times L \times H$ 的空间再次用于 $\nabla Y$ 的 reshape 或其他中间结果
-
$\nabla S$ 的空间在 Dropout 与 Softmax 反向计算之间复用
- $\nabla S$ 在计算时先经过 Dropout,再经过 Softmax 的梯度
- 同一块空间在两个阶段可以被循环利用,不需要两份副本
-
$\nabla V, \nabla Q, \nabla K$ 的存储也通过复用避免额外的拷贝
- 比如 $\nabla V$ 计算完后可以重用为 $\nabla Q$ 的中间存储。
通过这些策略,多个中间梯度不再各自占用独立内存,而是在不同时间阶段复用同一块内存区域,达到节省显存的目的。
5.3 显存瓶颈与复用效果
图中右侧标出了两类区域:
-
Bottleneck(瓶颈): 主要是 $\nabla S$ 阶段,因为其尺寸为 $ B \times L^2 \times H $,当 L 较大时(如几千 token),这是反向传播中占用显存最多的部分。
-
Least Memory Allocation(最小内存分配): 通过上述内存复用,整个自注意力反向传播过程中,显存的最大占用被控制在: $ \max{B \times L^2 \times N,\ 3 \times B \times L \times H} $ 其中 $ N $ 是注意力头数(number of heads)。 相较于 naive 实现,省去了大量不必要的中间 buffer 分配。
5.4 实际意义
在大模型训练中,自注意力反向传播是显存占用最集中的部分之一。 如果不做内存复用,每一层都可能临时分配数十到上百 MB 的中间梯度张量,在数百层 Transformer 堆叠时,显存压力极大
通过这种内存复用策略,可以在不改变计算逻辑的前提下:
- 显著降低峰值显存占用
- 提高 GPU 内存利用率
- 为更大的 batch size 或更长的序列长度腾出空间
6 加速策略总结
主要思路:
-
前向和反向计算的高效算子kernel(见上篇:算子融合与减少同步)
-
高效的参数更新(本文 §4 混合精度)
-
高效的显存管理(本文 §5 反向传播显存复用)