1 回顾大规模模型训练
1.1 扩大训练规模的策略
1.1.1 切分数据(Data Parallelism)
- Single Node Multi-GPU
- DDP(Distributed Data Parallel)
- Parameter Server 模式
1.1.2 切分模型(Model Parallelism)
- 模型并行(Model Parallel)
- 流水线并行(Pipeline Parallel, PP)
- 张量并行(Tensor Parallel, TP)
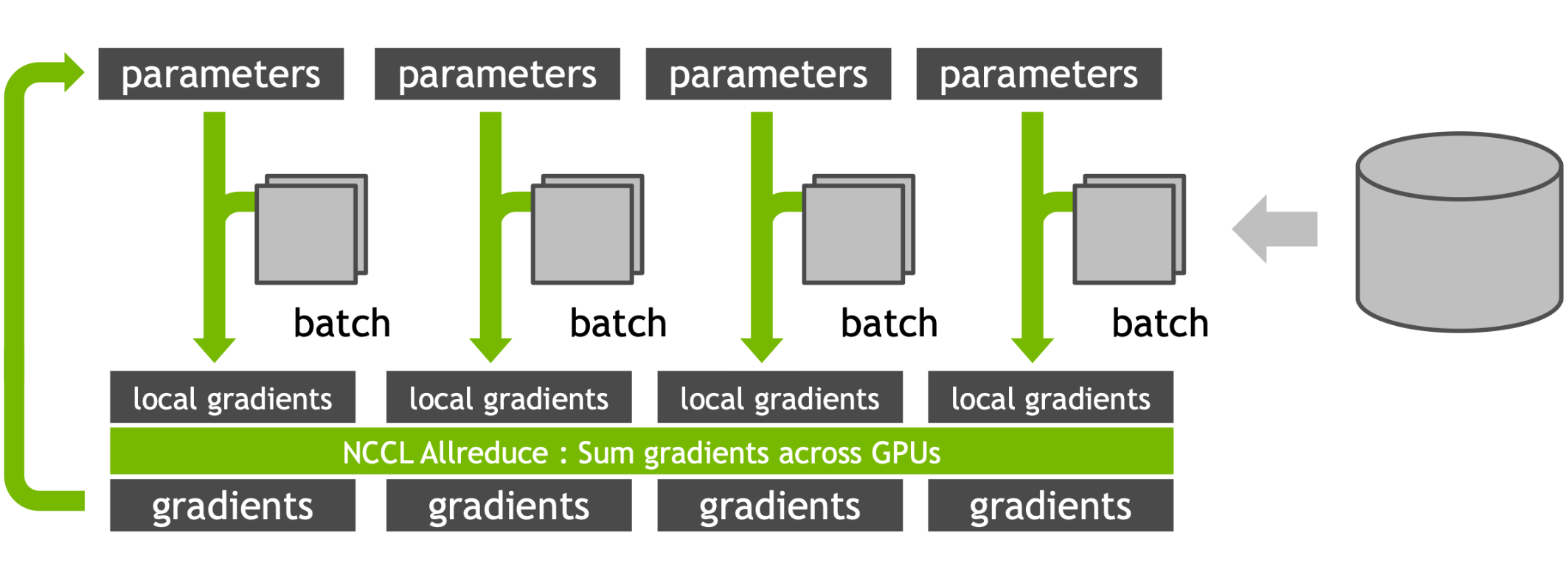
要点: 无论是数据并行还是模型并行,都需要跨 GPU 传递梯度(communicate gradients across GPUs)。
2 多卡通信 Multi-GPU Communication
2.1 NCCL 简介 (NVIDIA Collective Communication Library)
- 提供 GPU 间通信 API
- 支持 集体通信(Collective) 和 点对点(P2P) 模式
-
支持多种互联技术:
- PCIe
- NVLink
- InfiniBand
- IP sockets
- 所有操作均与 CUDA 流绑定(CUDA Stream)
2.2 NCCL 通信原语 (Primitives)
通信原语详解(含 Ring 实现与通信量分析):NCCL 通信原语
2.2.1 Broadcast
从 root rank 广播数据到所有设备。
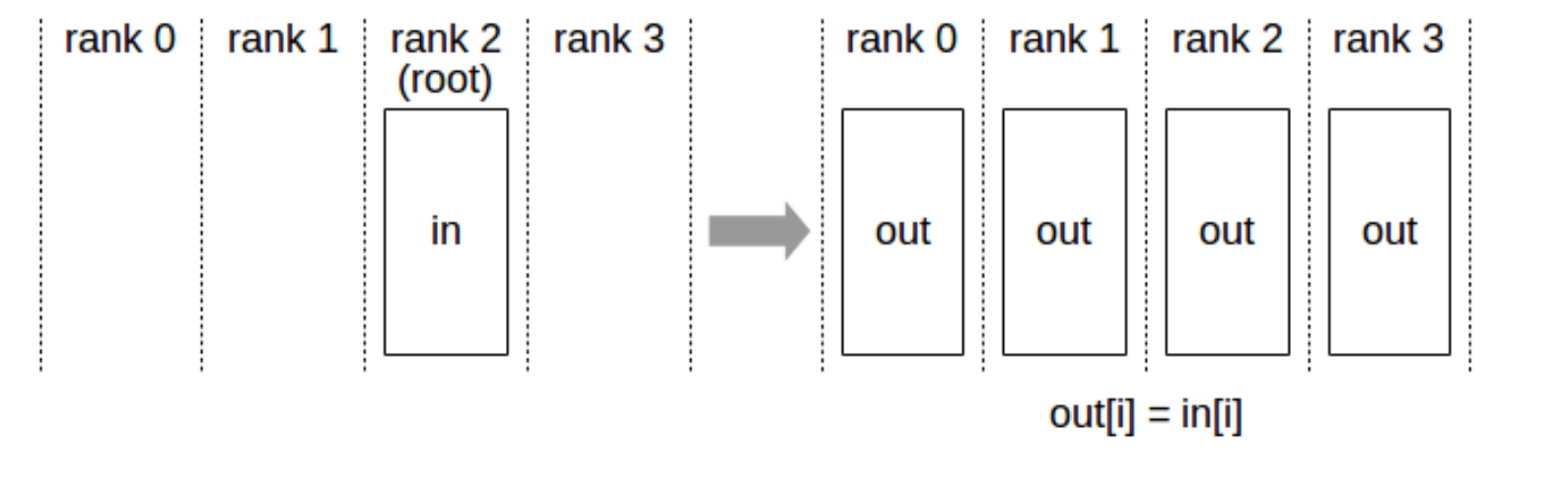
接口:
ncclResult_t ncclBroadcast(const void* sendbuff, void* recvbuff,
size_t count, ncclDataType_t datatype,
int root, ncclComm_t comm, cudaStream_t stream)
2.2.2 Reduce
执行规约计算(如 max, min, sum),并将结果写入指定的 rank。
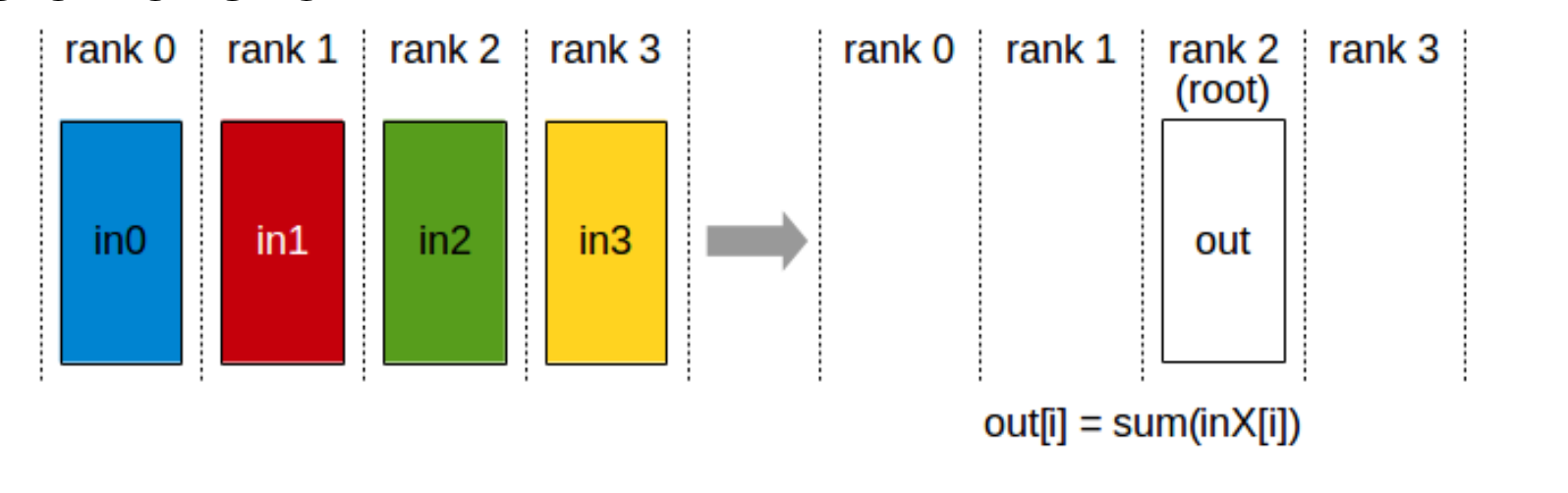
ncclResult_t ncclReduce(const void* sendbuff, void* recvbuff,
size_t count, ncclDataType_t datatype, ncclRedOp_t op,
int root, ncclComm_t comm, cudaStream_t stream)
2.2.3 ReduceScatter
计算规约算子,然后 把结果分到不同的 rank
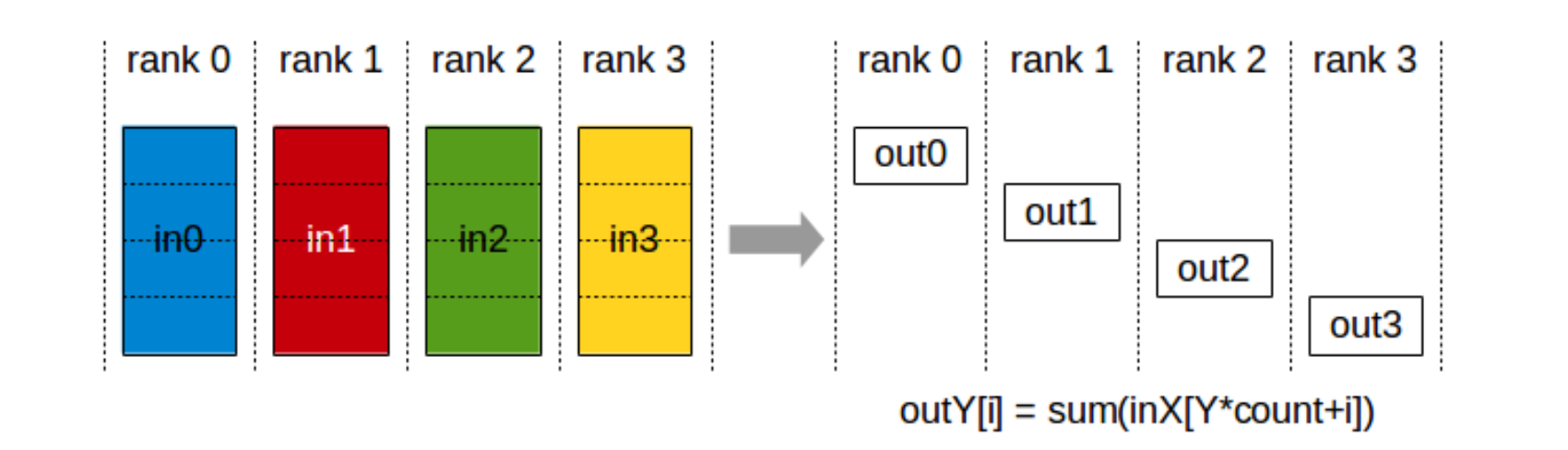
ncclResult_t ncclReduceScatter(const void* sendbuff,
void* recvbuff , size_t recvcount, ncclDataType_t datatype,
ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream)
2.2.4 AllGather
从 $k$ 个 rank 收集各自的 $N$ 个值,形成大小为 $k \times N$ 的输出,并广播给所有 rank。
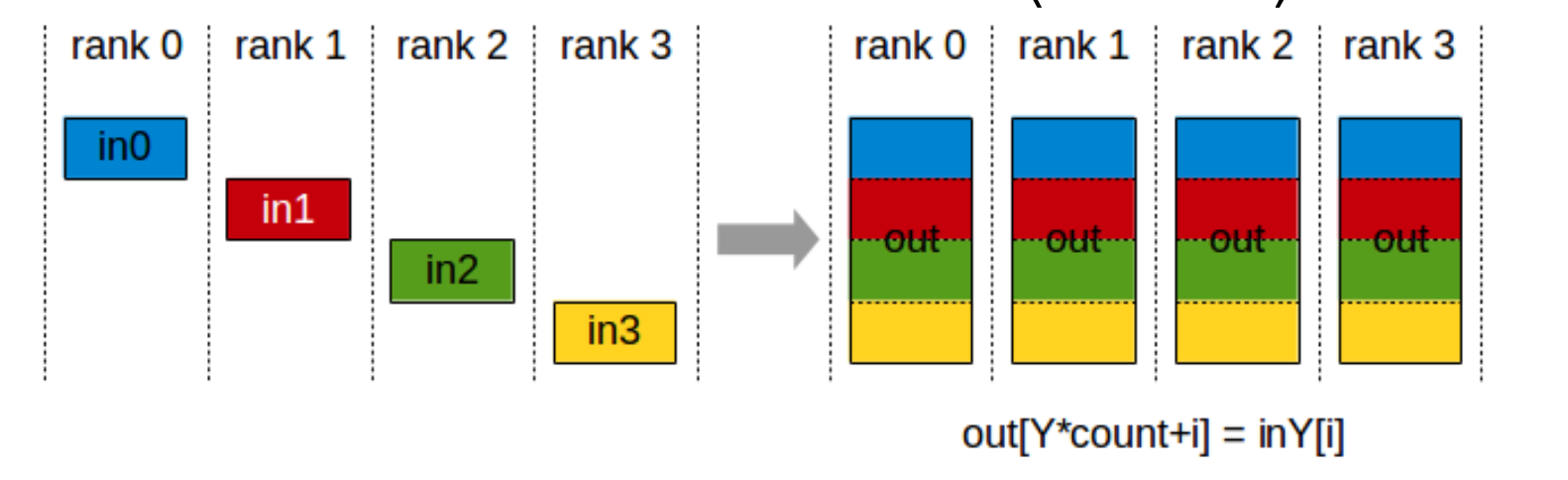
ncclResult_t ncclAllGather(const void* sendbuff,
void* recvbuff, size_t sendcount, ncclDataType_t datatype,
ncclComm_t comm, cudaStream_t stream)
2.2.5 AllReduce
等价于 Reduce + Broadcast(或 ReduceScatter + AllGather)。
就是reuduce 后 再广播 下
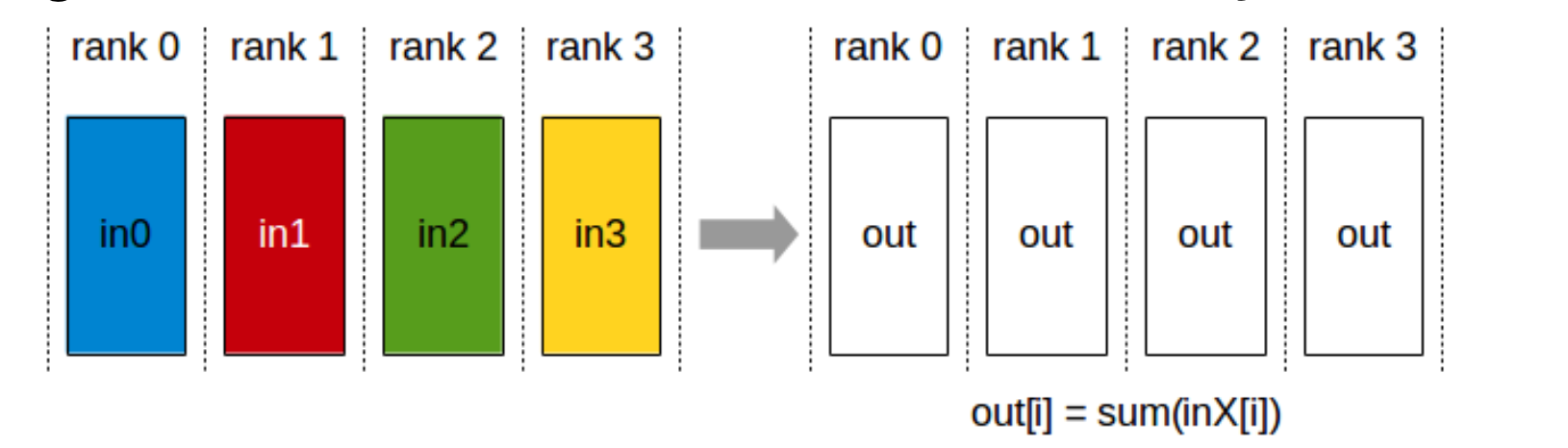
ncclResult_t ncclAllReduce(const void* sendbuff,
void* recvbuff , size_t count, ncclDataType_t datatype,
ncclRedOp_t op, ncclComm_t comm, cudaStream_t stream)
2.3 CUDA 中的数据指针类型
有三种
- 设备内存(device memory):位于 CUDA 设备本地的显存;
- 主机内存(host memory):通过
cudaHostRegister或cudaGetDevicePointer注册后,可被设备访问的主机内存; - 统一内存(managed and unified memory):由 CUDA 统一管理、可在主机与设备间自动迁移的数据内存。
2.4 P2P 通信示例
ncclGroupStart();
ncclSend(sendbuff, sendcount, sendtype, peer, comm, stream);
ncclRecv(recvbuff, recvcount, recvtype, peer, comm, stream);
ncclGroupEnd();
2.5 Ring AllReduce 实现原理
N 张 GPU 构成一个环,执行 $2(N-1)$ 步:
- 前 $N-1$ 步执行 Scatter/Reduce
- 后 $N-1$ 步执行 All-Gather
// 初始化 NCCL。由于在每个线程/进程中会在多张 GPU 上调用 ncclCommInitRank, initializing NCCL, group API is required around ncclCommInitRank as it is
// 因此需要用 Group API 将这些调用包裹起来 called across multiple GPUs in each thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++) {
CUDACHECK(cudaSetDevice(localRank*nDev + i));
NCCLCHECK(ncclCommInitRank(comms+i, nRanks*nDev, id, myRank*nDev + i));
}
NCCLCHECK(ncclGroupEnd());
// 调用 NCCL 通信 API。当一个线程/进程中包含多张 GPU 时 calling NCCL communication API. Group API is required when using
// 也同样需要用 Group API 将多次通信调用打包在一起 multiple devices per thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++)
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size,
ncclFloat, ncclSum, comms[i], s[i]));
NCCLCHECK(ncclGroupEnd());
// 在 CUDA 流上同步,以确保所有 NCCL 通信操作完成 synchronizing on CUDA stream to complete NCCL communication
for (int i=0; i<nDev; i++)
CUDACHECK(cudaStreamSynchronize(s[i]));
3 DDP 数据并行
3.1 DDP 基本机制
3.1.1 数据并行基本思想
- 在多张 GPU 上创建模型副本;
- 每个副本独立执行前向与反向传播;
- 在 optimizer step 前同步梯度。
3.1.2 DDP 设计目标
- 非侵入性(Non-intrusive):开发者无需重写原有单机训练逻辑
- 可拦截性(Interceptive):能拦截信号、触发高效通信算法,并暴露内部优化机会
3.1.3 DDP 梯度同步机制
(1) 朴素方案(Naïve Solution)
在反向传播结束后统一同步所有梯度
问题:同步过频或粒度太细,通信开销大。
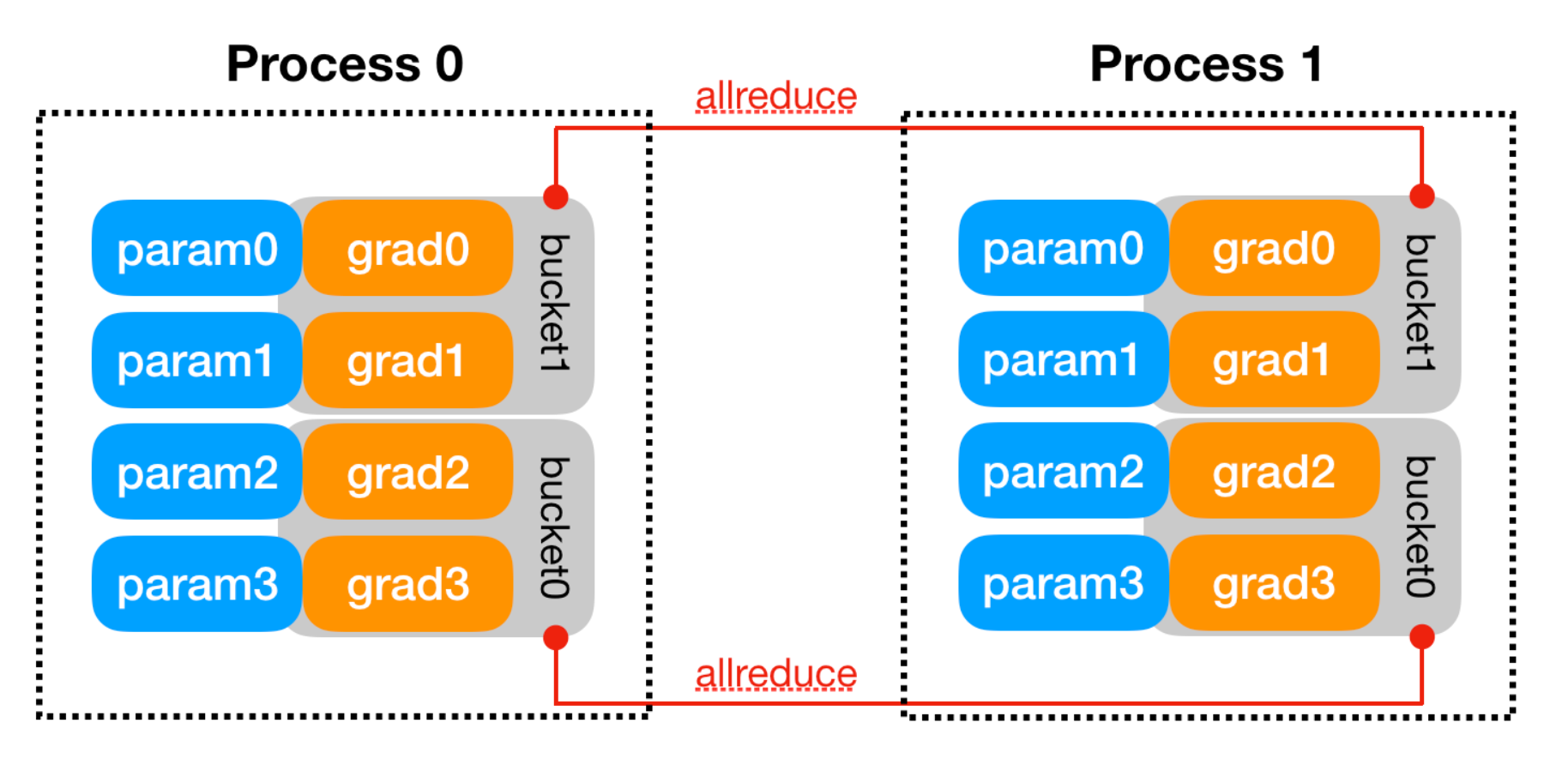
(2) 梯度分桶机制(Gradient Bucketing)
- 将参数梯度划分为多个 bucket;
- 每个 bucket 包含多个梯度张量;
- 模型参数会按照 model.parameters() 返回顺序的大致反序分配到不同的 bucket 中
- DDP 期望在反向传播过程中,梯度会大致按照这个顺序依次计算完成。
- 当一个 bucket 中的所有梯度计算完成时,立刻异步启动 AllReduce;
- 以此实现 计算-通信重叠(overlap of computation and communication)。
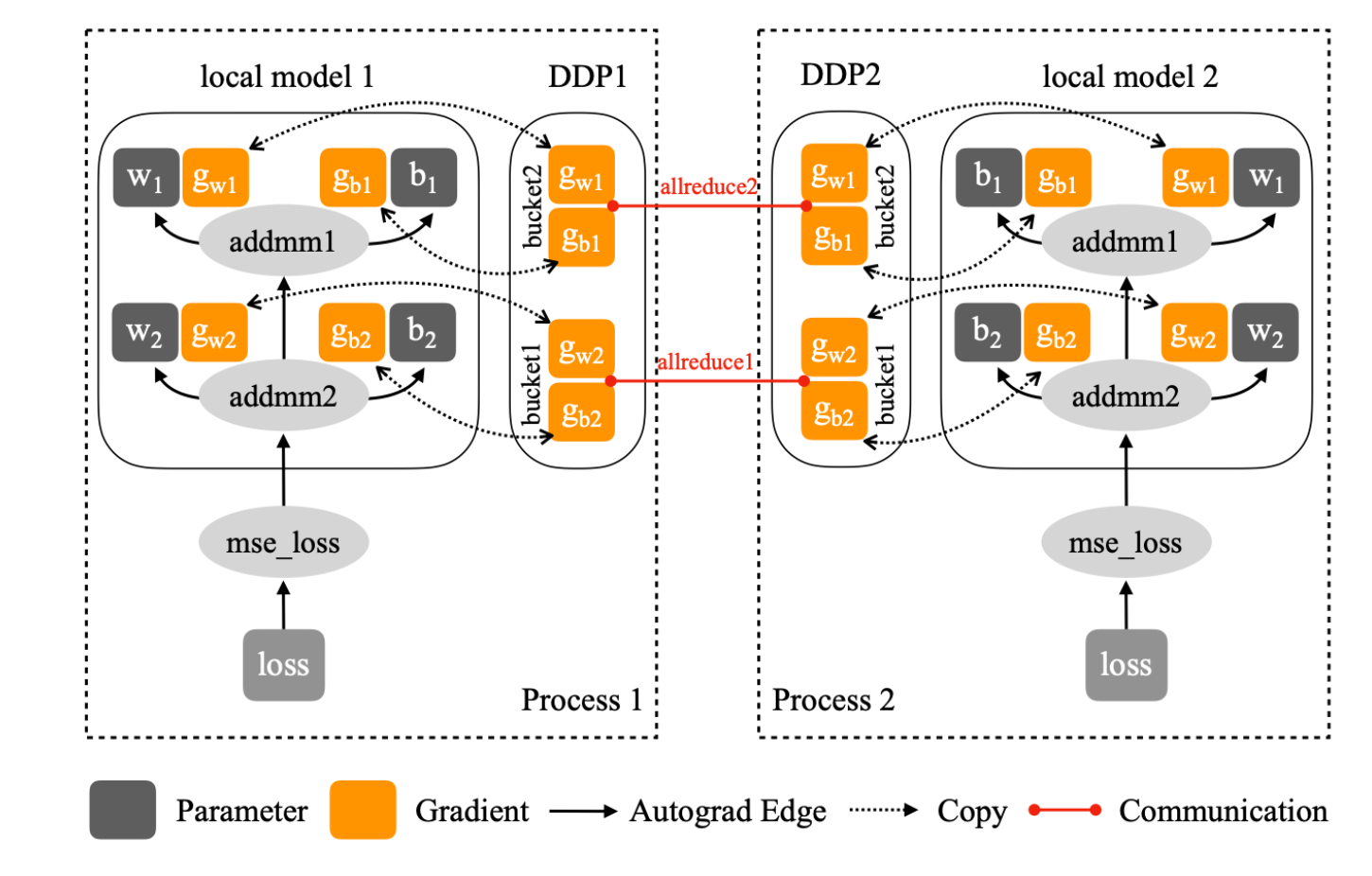
(3) 梯度规约(Gradient Reduction)
- 每个进程(Process 1、Process 2)都维护着一份相同的模型副本(local model 1 / local model 2)。
- 反向传播(backward)过程中,各自独立计算参数梯度(gradients),
- 然后通过 AllReduce 通信 把这些梯度在所有进程间求平均
3.2 DDP Reducer 实现细节
- Autograd 钩子触发:某个参数的梯度就绪 → autograd_hook(index)
// The function `autograd_hook` is called after the gradient for a
// model parameter has been accumulated into its gradient tensor.
// This function is only to be called from the autograd thread.
// autograd 在线程中调用:某参数的梯度已累加完成后触发
void Reducer::autograd_hook(size_t index) {
std::lock_guard<std::mutex> lock(this->mutex_);
if (!first_autograd_hook_called_) {
first_autograd_hook_called_ = true;
num_bwd_calls_++;
}
// See Note [Skip allreducing local_used_map_dev]
// 处理“发现未用参数”或“静态图首次迭代”:仅当该参数梯度已定义时标记本地使用
if (dynamic_graph_find_unused() || static_graph_first_iteration()) {
// Since it gets here, this param has been used for this iteration. We want
// to mark it in local_used_map_. During no_sync session, the same var can
// be set multiple times, which is OK as does not affect correctness. As
// long as it is used once during no_sync session, it is marked as used.
// Only set it as locally used if the grad is defined. Otherwise, hooks can
// be fired with undefined grads, such as when not all outputs are used in
// DDP when computing loss. In this case, we don't want to mark it as
// locally used to ensure we don't touch the parameter's .grad field.
auto& variable = get_param_from_index(index);
runGradCallbackForVariable(variable, [&](auto& grad) {
if (grad.defined()) {
local_used_map_[static_cast<int64_t>(index)] = 1;
}
// The gradient is never modified.
return false;
});
}
if (static_graph_first_iteration()) {
numGradHooksTriggeredMap_[index] += 1;
return;
}
// Ignore if we don't expect to be called.
// This may be the case if the user wants to accumulate gradients
// for number of iterations before reducing them.
if (!expect_autograd_hooks_) {
return;
}
grad_ready_order_indices_.push_back(static_cast<int64_t>(index));
// If `find_unused_parameters_` is true there may be model parameters that
// went unused when computing the model output, they won't be part of the
// autograd graph, and won't receive gradients. These parameters are
// discovered in the `prepare_for_backward` function and their indexes stored
// in the `unused_parameters_` vector.
if (!has_marked_unused_parameters_) {
has_marked_unused_parameters_ = true;
for (const auto& unused_index : unused_parameters_) {
mark_variable_ready(unused_index); // 真正标记该参数就绪
}
}
// Rebuild bucket only if 1) it is the first time to rebuild bucket 2)
// static_graph_ is true or find_unused_parameters_ is false,
// 3) this backward pass needs to run allreduce.
// Here, we just dump tensors and their parameter indices into
// rebuilt_params_ and rebuilt_param_indices_ based on gradient arriving
// order, and then at the end of finalize_backward(), buckets will be
// rebuilt based on rebuilt_params_ and rebuilt_param_indices_, and then
// will be broadcasted and initialized.
// If it is static graph, after 1st iteration, check if a variable
// is ready for communication based on numGradHooksTriggeredMap_.
// 如需按到达顺序重建 buckets,则收集参数
if (static_graph_after_first_iteration()) {
REDUCER_CHECK(
numGradHooksTriggeredMapPerIteration_[index] > 0,
logger_,
"Your training graph has changed in this iteration, ",
"e.g., one parameter is unused in first iteration, but ",
"then got used in the second iteration. this is not ",
"compatible with static_graph set to True.");
if (--numGradHooksTriggeredMapPerIteration_[index] == 0) {
if (should_rebuild_buckets()) {
push_rebuilt_params(index);
}
// Finally mark variable for which this function was originally called.
mark_variable_ready(index);
}
} else {
if (should_rebuild_buckets()) {
push_rebuilt_params(index);
}
// Finally mark variable for which this function was originally called.
mark_variable_ready(index);
}
}
- 标记梯度就绪:mark_variable_ready(index) 把该参数归入其所属的 bucket;当 bucket 内所有梯度就绪时:
// 把某个参数标记为“梯度就绪”,并写入其所属 bucket
void Reducer::mark_variable_ready(size_t variable_index) {
REDUCER_CHECK(
variable_index < variable_locators_.size(),
logger_,
"Out of range variable index.");
checkAndRaiseMarkedTwiceError(variable_index);
perIterationReadyParams_.insert(variable_index);
backward_stats_[variable_index] =
current_time_in_nanos() - backward_compute_start_time_;
// Any time we mark a variable ready (be it in line due to unused parameters,
// or via an autograd hook), we require a call to the finalize function. If
// this doesn't happen before the next iteration (or call to
// `prepare_for_backwards`), we know something is wrong.
require_finalize_ = true; // 本轮 backward 需要收尾
const auto& bucket_index = variable_locators_[variable_index];
auto& bucket = buckets_[bucket_index.bucket_index];
set_divide_factor();
// 按稠密/稀疏分别写入 bucket
if (bucket.expect_sparse_gradient) {
mark_variable_ready_sparse(variable_index);
} else {
mark_variable_ready_dense(variable_index);
}
// TODO(@pietern): Make this work for both CPU/CUDA tensors.
// When using CPU tensors we don't need to do this.
// Record event so that we can wait for all of them.
// auto& event = bucket.events[bucket_index.intra_bucket_index];
// event.record();
// Check if this was the final gradient for this bucket.
// 若该 bucket 全部梯度就绪,则推进到下一个阶段
if (--bucket.pending == 0) {
mark_bucket_ready(bucket_index.bucket_index);
}
// Run finalizer function and kick off reduction for local_used_map once the
// final bucket was marked ready.
// 若所有 bucket 均已就绪,排队回调做收尾与可能的 bucket 重建
if (next_bucket_ == buckets_.size()) {
if (dynamic_graph_find_unused()) {
all_reduce_local_used_map();
}
torch::autograd::Engine::get_default_engine().queue_callback([this] {
std::lock_guard<std::mutex> lock(this->mutex_);
if (should_collect_runtime_stats()) {
record_backward_compute_end_time();
}
// Check that all buckets were completed and had their work kicked off.
TORCH_INTERNAL_ASSERT(next_bucket_ == buckets_.size());
if (static_graph_after_first_iteration() && should_rebuild_buckets()) {
for (const auto& unused_index : unused_parameters_) {
push_rebuilt_params(unused_index);
}
}
this->finalize_backward();
});
}
}
- bucket 就绪:mark_bucket_ready(bucket_index) 顺序触发该 bucket 的 AllReduce(或通信 hook)。
// Called when the bucket at the specified index is ready to be reduced.
// 指定下标的 bucket 就绪:按顺序触发规约/通信
void Reducer::mark_bucket_ready(size_t bucket_index) {
TORCH_INTERNAL_ASSERT(bucket_index >= next_bucket_);
// Buckets are reduced in sequence. Ignore this bucket if
// it's not its turn to be reduced.
// 只按顺序处理:不是当前应处理的 bucket 则先返回
if (bucket_index > next_bucket_) {
return;
}
// Keep going, until we either:
// - have kicked off reduction for all buckets, or
// - found a bucket that's not yet ready for reduction.
// 处理所有已就绪的连续 bucket
for (; next_bucket_ < buckets_.size() && buckets_[next_bucket_].pending == 0;
next_bucket_++) {
num_buckets_ready_++;
if (num_buckets_ready_ == 1 && should_collect_runtime_stats()) {
record_backward_comm_start_time();
}
auto& bucket = buckets_[next_bucket_];
if (!should_skip_all_reduce_bucket(bucket)) {
all_reduce_bucket(bucket);
num_buckets_reduced_++;
}
}
}
-
发起通信:all_reduce_bucket(bucket) 打包为 GradBucket,交给 run_comm_hook(默认实现即 AllReduce)。
-
全部 bucket 处理完:排队一个回调,调用 finalize_backward() 做收尾(必要时处理 find_unused_parameters、重建 bucket 等)
// 对一个 bucket 发起通信:打包为 GradBucket,交由通信 hook 处理(默认 AllReduce)
void Reducer::all_reduce_bucket(Bucket& bucket) {
auto variables_for_bucket = get_variables_for_bucket(next_bucket_, bucket);
// TODO(@pietern): Ensure proper synchronization with the CUDA events
// that recorded copies into this `gradients` tensor. If these copies are
// executed on non-default streams, the current stream for the device
// that holds the `gradients` tensor must wait on these events.
//
// As long as autograd uses the default stream for every device,
// these operations are implicitly sequenced, and we don't need to
// do any extra synchronization here.
const auto& tensor = bucket.gradients;
GradBucket grad_bucket(
next_bucket_, // 当前 bucket 序号
buckets_.size(), // 当前 bucket 序号
tensor, // 聚合后的梯度大张量
bucket.offsets, // 各小梯度在大张量中的偏移
bucket.lengths, // 各小梯度长度
bucket.sizes_vec, // 各小梯度原始形状
variables_for_bucket, // 对应的参数变量
bucket.sparse_tensor_indices // 稀疏时的索引
);
bucket.future_work = run_comm_hook(grad_bucket);// 异步通信任务(可自定义 hook)
}
3.3 梯度同步算法
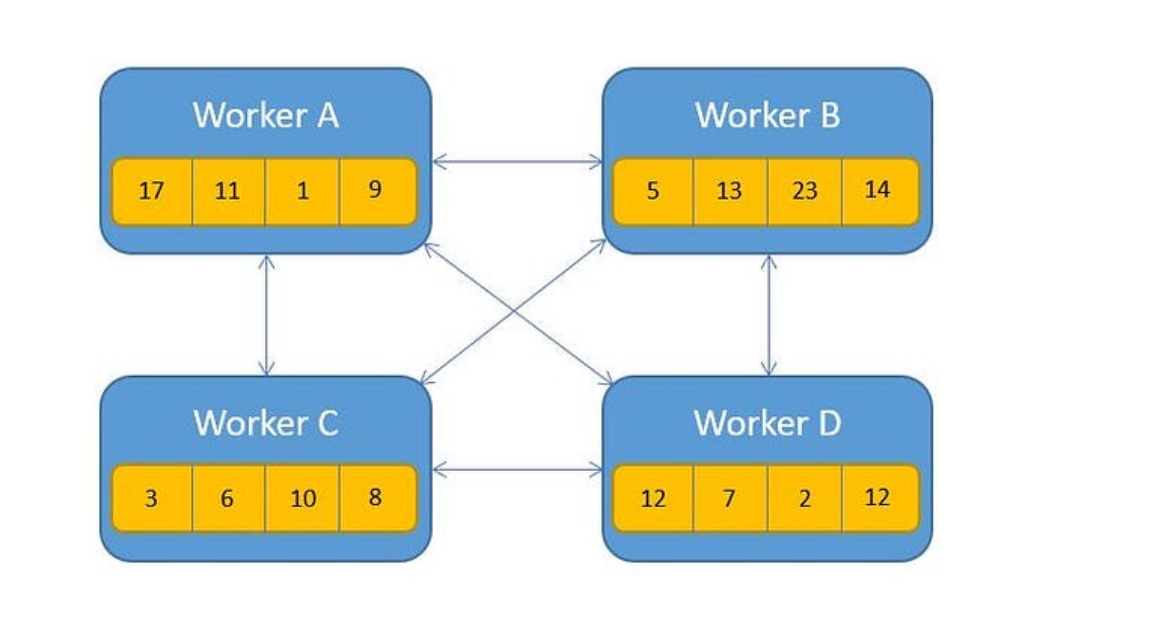
3.3.1 Naïve All-Reduce
最基础的实现方式,直接在所有 GPU 之间全量同步梯度
3.3.2 Ring All-Reduce
更高效的实现,使用环形拓扑结构进行 Scatter-Reduce + All-Gather:
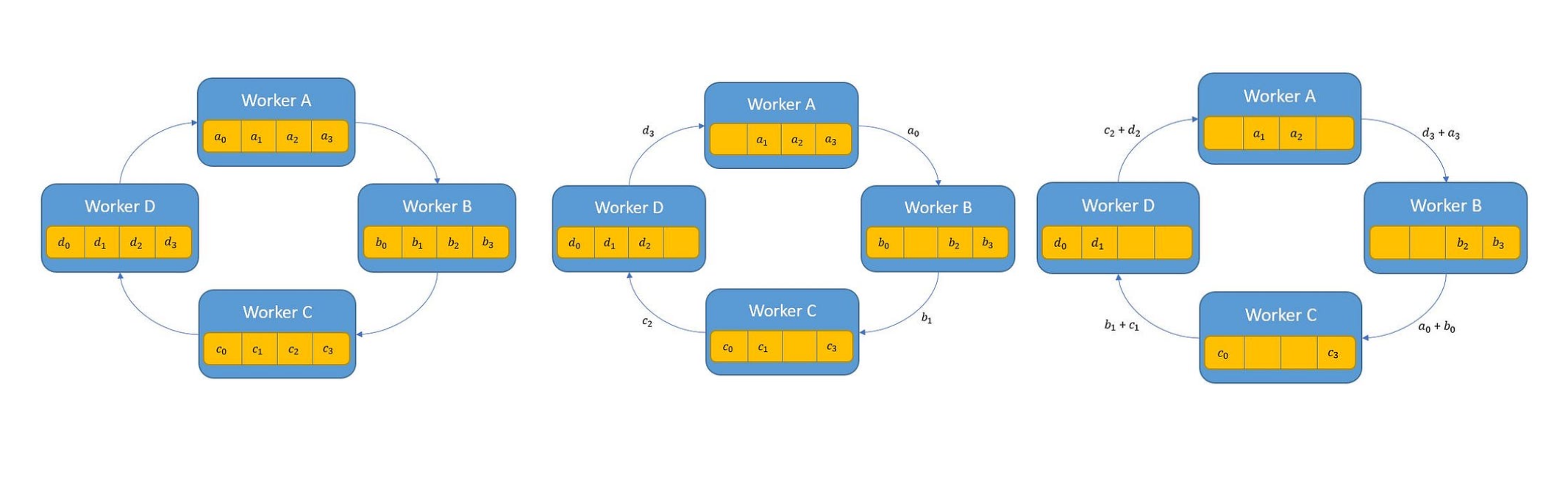
(1) Scatter-Reduce 阶段
for (int i = 0; i < size - 1; i++) {
int recv_chunk = (rank - i - 1 + size) % size;
int send_chunk = (rank - i + size) % size;
float* segment_send = &(output[segment_ends[send_chunk] -
segment_sizes[send_chunk]]);
MPI_Irecv(buffer, segment_sizes[recv_chunk],
datatype, recv_from, 0, MPI_COMM_WORLD, &recv_req);
MPI_Send(segment_send, segment_sizes[send_chunk],
MPI_FLOAT, send_to, 0, MPI_COMM_WORLD);
float *segment_update = &(output[segment_ends[recv_chunk] -
segment_sizes[recv_chunk]]);
// Wait for recv to complete before reduction
MPI_Wait(&recv_req, &recv_status);
reduce(segment_update, buffer, segment_sizes[recv_chunk]);
}
(2) All-Gather 阶段
实现 Implementing All-gather
for (size_t i = 0; i < size_t(size - 1); ++i) {
int send_chunk = (rank - i + 1 + size) % size;
int recv_chunk = (rank - i + size) % size;
// Segment to send - at every iteration we send segment (r+1-i)
float* segment_send = &(output[segment_ends[send_chunk] -
segment_sizes[send_chunk]]);
// Segment to recv - at every iteration we receive segment (r-i)
float* segment_recv = &(output[segment_ends[recv_chunk] -
segment_sizes[recv_chunk]]);
MPI_Sendrecv(segment_send, segment_sizes[send_chunk],
datatype, send_to, 0, segment_recv,
segment_sizes[recv_chunk], datatype, recv_from,
0, MPI_COMM_WORLD, &recv_status);
}