1 Parameter Efficient Fine-Tuning 概述
1.1 全参数微调成本
全参数微调(Full Parameter Fine-Tuning)在大模型上代价极高。 以半精度(FP16/BF16)微调参数规模为 $N$ 的模型为例,显存占用可按如下估算:
- 权重(Weights):$2 \text{ bytes} \times N$
- 权重梯度(Gradients):$2 \text{ bytes} \times N$
- 优化器状态(Optimizer States):$2 \times 2 \text{ bytes} \times N = 4 \text{ bytes} \times N$
- 激活值(Activations):约为参数量的 $1\sim2$ 倍
例如 LLaMA-8B 模型,在全参数训练时大约需要 80GB 显存。
2 LoRA: Low-Rank Adaptation(或 CIAT:Counter-Interference Adapter)
2.1 核心思想:低秩矩阵分解
LoRA 通过冻结原始参数,仅对注意力层的权重矩阵 $(W_Q, W_K, W_V, W_O)$ 进行 低秩分解(Low-Rank Decomposition):
\[\Delta W = A \cdot B\]其中:
- $A \in \mathbb{R}^{d \times r}$
- $B \in \mathbb{R}^{r \times k}$
- $r$ 为低秩维度(rank)
更新时只对 $A$ 和 $B$ 进行梯度优化,而原始权重 $W$ 冻结不变。 注意:LoRA 不应用于前馈网络(FFN) 的线性层,因为这些层主要用于知识存储。
2.2 推理阶段(Inference)
推理时,使用合成权重:
\[W' = W + A \cdot B\]这样仅需在显存中额外存储少量 $A, B$ 参数(例如 $r = 8$ 或 $16$)。 框架如 vLLM 已原生支持不同 LoRA 权重的动态切换。
2.3 反向传播机制
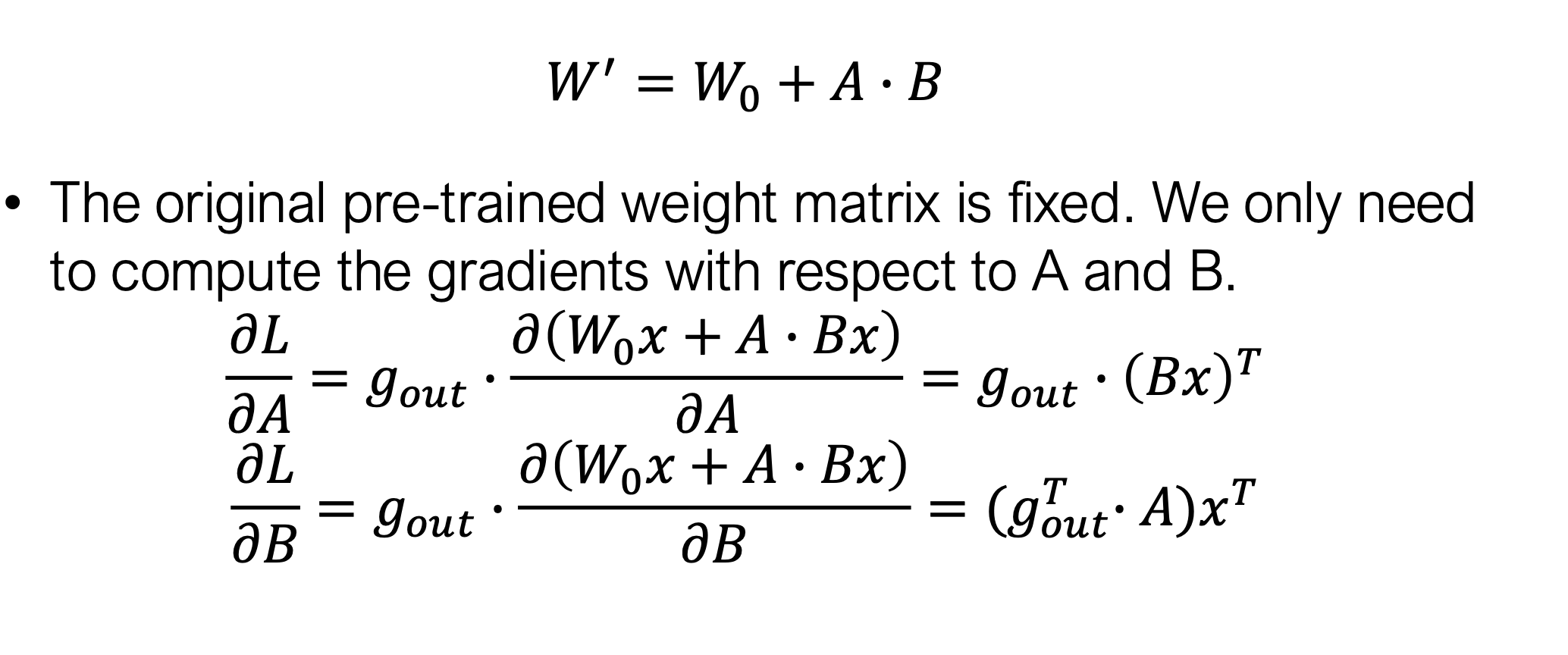
2.4 显存节省效果
以 LLaMA-8B 模型为例:
| 项目 | 全参数微调 | 使用 LoRA / CIAT |
|---|---|---|
| 参数量 | 8B | 4M |
| 权重存储(BF16) | 16GB | 8MB |
| 优化器状态(Adam) | 48GB | 24MB |
显存节省达 数千倍,极大降低训练门槛。
2.5 Rank 选择
Rank 增大会增加可训练参数,但超过一定阈值后收益迅速递减。 实践中一般取 $r = 8$ 即能取得较佳平衡
3 QLoRA: Quantization + Low-Rank Training
3.1 基本流程
QLoRA 结合了量化(Quantization)与低秩适配(LoRA)的思想。 其训练过程涉及两种精度类型:
-
双重量化(Double Quantize): 将模型权重量化为 NF4 格式,以节省显存和存储空间。
-
双重反量化(Double De-quantize): 在计算时,将量化后的权重从 NF4 反量化回 BF16 格式,用于前向与反向计算。
-
前向与反向传播(Forward & Backward Pass): 在 BF16 精度下执行模型的前向传播与反向传播运算。
-
梯度计算(Gradient Computation): 仅对 LoRA 参数 计算梯度(BF16 精度),而基础权重保持冻结不更新。
参考;Dettmers et al. QLORA: Efficient Finetuning of Quantized LLMs. NeurIPS 2023.
3.2 4-bit 表示机制
QLoRA 通常使用 4-bit NF4 格式 表示权重,其核心思想是:
- 将数值范围映射到正态分布区间;
- 使用非均匀量化方案,在权重分布较密集处分配更多的量化位;
- 实现比 INT4 更优的量化精度。
3.3 QLoRA Code Walkthrough
https://github.com/artidoro/qlora/blob/main/examples/guanaco_7B_demo_colab.ipynb