1 LLM 训练中的显存占用
1.1 DDP 下的显存占用
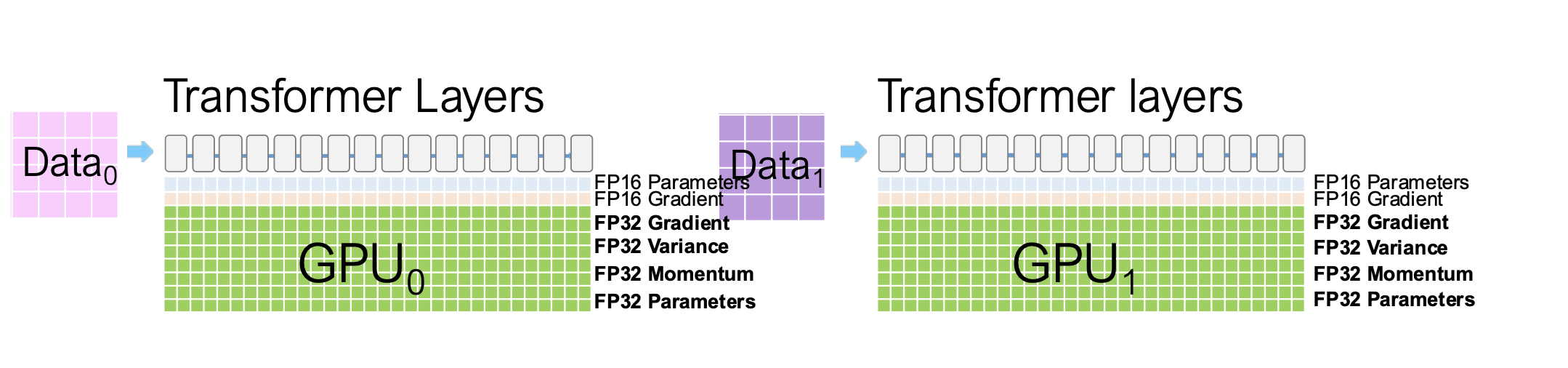
在 DDP (Distributed Data Parallel) 训练模式下:
1.1.1 主要的显存
- 每张 GPU 都需要保存一份完整的 模型参数(Model Parameters)、梯度(Gradients) 和 优化器状态(Optimizer States)。
- 因此总显存开销与 GPU 数量线性相关,难以扩展到更大模型
1.1.2 其他的显存
1.1.2.1 临时缓冲区(Temporary Buffers)
在执行如 梯度 All-Reduce 或 梯度范数计算(Gradient Norm Computation) 时, 系统通常会将所有梯度融合到一个 单一的扁平缓冲区(flattened buffer) 中再执行运算,以提升吞吐性能。
1.1.2.2 显存碎片化(Memory Fragmentation)
显存碎片化是训练过程中隐性的显存浪费来源。 在极端情况下,碎片化造成的额外显存浪费可能高达 30%。
2 DP 并行下的显存拆分与优化
2.1 目的
在 DDP 并行 下尽可能减少显存占用,以便训练更大的模型。 核心思想是:通过划分与共享机制,减少参数、梯度和优化器状态的冗余副本。
2.2 常见的显存优化手段
- ZeRO 技术:通过划分(Partition)优化器状态、梯度与模型参数,降低显存占用。
- 激活显存优化(Activation Memory Reduction): 采用 激活检查点(Activation Checkpointing) 或 激活压缩(Activation Compression)。
- CPU Offload(显存卸载):将部分模型参数或优化器状态转移到 CPU。 缺点是带来高达 50% 的训练时间开销。
- 高效优化器(Memory Efficient Optimizer): 仅维护粗粒度统计信息,减少优化器状态显存。
3 ZeRO 技术详解
| Stage | 划分对象 | 描述 |
|---|---|---|
| ZeRO-1 | 优化器状态 (Optimizer States) | 每 GPU 仅保存一部分优化器状态 |
| ZeRO-2 | 梯度 (Gradients) | 进一步分区梯度 |
| ZeRO-3 | 参数 (Parameters) | 分区模型参数,实现最大显存节省 |
Deepspeed 实现了完整的 ZeRO 系列方案。
3.1 拆分优化器状态(ZeRO-1)
划分优化器状态(Partition optimizer states):,将优化器状态分成 K 个分区(partitions),每个 GPU 只负责其中一个分区,从而减少单卡显存占用
- 每个GPU更新局部fp16 梯度
- all reduce 取平均计算全局FP32 梯度
- 更新fp32 的优化器状态
- 更新fp16 剃度
3.2 拆分梯度(ZeRO-2)
以 4 张 GPU 为例:
- 在反向传播过程中:GPU0、GPU1、GPU2 会暂时保存属于 GPU3 负责参数分区(M3) 的梯度缓冲区
- GPU0、GPU1、GPU2 将这些 M3 对应的梯度通过 ncclReduce 操作发送给 GPU3, 在 GPU3 上执行梯度求和reduce
- 随后,GPU0、GPU1、GPU2 删除本地的 M3 梯度临时缓冲, 只有 GPU3 保留聚合后的 M3 梯度结果
- 继续反向传播:此时 GPU0、GPU1、GPU3 会暂时保存属于 GPU2 负责参数分区(M2) 的梯度缓冲区
- GPU0、GPU1、GPU3 将这些 M2 梯度通过 ncclReduce 操作发送给 GPU2,在 GPU2 上进行聚合
- 然后,GPU0、GPU1、GPU3 删除 M2 梯度, GPU2 保留聚合后的 M2 梯度
- 接下来,以相同的方式继续反向传播并聚合 M1 梯度、M0梯度
- 最终,每张 GPU 仅保留自己负责参数的梯度副本
3.3 拆分模型参数(ZeRO-3)
四卡训练流程
3.3.1 参数划分
将模型参数划分为 K 个分区(partitions),每张 GPU 只保存自己负责的部分:
GPU0 → Part 1
GPU1 → Part 2
GPU2 → Part 3
GPU3 → Part 4
3.3.2 前向传播阶段
-
第一部分(Part 1)计算: GPU0 将自己持有的参数通过 ncclBroadcast 广播到 GPU1、GPU2、GPU3。 所有 GPU 使用这部分参数进行前向计算。 计算完成后,GPU1、GPU2、GPU3 删除这部分参数,只有 GPU0 保留。
-
第二部分(Part 2)计算: GPU1 广播自己的参数给其他 GPU。 所有 GPU 计算第二部分层的前向。 GPU0、GPU2、GPU3 删除该部分参数,仅 GPU1 保留。
-
第三部分(Part 3)计算: GPU2 广播自己的参数给其他 GPU。 所有 GPU 计算第三部分层的前向。 GPU0、GPU1、GPU3 删除该部分参数,仅 GPU2 保留。
-
第四部分(Part 4)计算: GPU3 广播自己的参数给其他 GPU。 所有 GPU 计算第四部分层的前向。
每次只有一个 GPU 拥有完整参数分区,其余 GPU 在需要计算时从该卡获取参数,用完即删除,从而显著降低显存占用。
3.3.3 反向传播阶段
-
第四部分(Part 4)反向计算: 所有 GPU 使用 GPU3 的参数执行反向传播。 每张 GPU 计算本地梯度后,将梯度通过 ncclReduce 归约到 GPU3。 GPU0、GPU1、GPU2 删除对应参数与梯度,GPU3 保留。
-
第三部分(Part 3)反向计算: GPU2 再次广播自己的参数到其他 GPU。 所有 GPU 执行反向传播,计算出本地梯度。 各 GPU 将梯度通过 ncclReduce 汇总到 GPU2,其他 GPU 删除参数与梯度,GPU2 保留。
-
第二部分与第一部分反向计算: 按同样流程依次进行:
- GPU1 广播 Part 2 → 所有 GPU 反向计算 → Reduce 到 GPU1。
- GPU0 广播 Part 1 → 所有 GPU 反向计算 → Reduce 到 GPU0。
ZeRO-3 的反向传播与 ZeRO-2 类似,但参数在反向时同样是按需加载和释放的。整个过程中,各 GPU 只持有当前分区需要的参数与梯度。
3.3.4 优化器更新阶段
- 每张 GPU 仅更新自己分区的 FP32 优化器状态(如 Adam 的
m、v)和参数。 - 参数更新完成后,等待下一轮前向传播时再根据需要广播。
3.4 ZeRO 显存占用总结
设 LLM 参数量为 $N$,每参数优化器状态占用 $M$ 字节,则:
| 阶段 | 显存占用 | 说明 |
|---|---|---|
| 原始 | $4N + M \cdot N$ | 完全冗余 |
| ZeRO-1 | $4N + \frac{M \cdot N}{K}$ | 优化器状态分区 |
| ZeRO-2 | $2N + \frac{(2+M)N}{K}$ | 梯度分区 |
| ZeRO-3 | $\frac{(4+M)N}{K}$ | 参数完全分区 |
ZeRO 显著降低显存占用,但会引入更多的通信开销。
3.5 ZeRO 通信开销分析
各通信原语(AllReduce / ReduceScatter / AllGather)的详细说明:NCCL 通信原语
- ZeRO Stage 1 与 Stage 2(优化器状态与梯度分区)
- 不会引入额外的通信开销,同时可实现最高约 8 倍的显存节省
- 其中 zero2 的 backward 通讯不是额外引入的
-
ZeRO Stage 3(参数分区)
- 在前向与反向过程中各需进行 两次参数广播(Broadcast),以及一次梯度归约(Reduce,与 ZeRO-2 相同)
- 因此,总通信开销约为 3 倍(2×Broadcast + 1×Reduce)
- 作为对比,传统实现(Baseline)通常需要执行 ScatterReduce + AllGather 操作
4 其他显存优化技术
4.1 ZeRO 降低激活显存占用
分区激活检查点(Partitioned Activation Checkpointing)
-
张量并行(Tensor Parallelism) 在设计上会导致激活(activations)在每个设备上都被复制一份,从而增加显存占用
-
为此,ZeRO 采用分区策略:
- 将每个激活张量切分到不同设备上,
- 仅在需要时再进行 聚合(gather),
- 以减少总体显存消耗
4.2 ZeRO 缓冲区管理(Buffers)
固定大小缓冲区(Constant Size Buffers)(类似于 PyTorch DDP 中的 Bucketing 机制)
-
缓冲区用于在执行 All-Reduce 时提升带宽利用率。
-
现代实现通常将所有参数融合(fuse)到一个单一的大缓冲区中,以减少通信开销。
-
ZeRO 采用固定大小的缓冲区设计,在大模型训练中能更高效地管理通信与内存
4.3 ZeRO 显存碎片整理(Memory Defragmentation)
- 长期驻留内存(Long-lived memory):如模型参数、优化器状态等,应当集中存放在一起,避免与易变数据混用。
- 短期内存(Short-lived memory):如可丢弃的激活值(discarded activations),与长期内存分离存储,以
- 减少显存碎片并提升分配效率
4.4 ZeRO 降低通信带宽(ZeRO++)
采用通信量化策略:
-
在前向传播(参数广播)阶段,对参数应用分块量化(block-wise quantization)技术, 将参数从 FP16 量化为 INT8,以减少通信带宽占用。 采用 zeropoint 量化(zeropoint quantization) 方法实现。
-
在反向传播的 ReduceScatter 阶段,同样应用量化, 将梯度从 FP16 量化为 INT8 或 INT4,进一步压缩通信数据量。
-
通过更合理的参数分区方式, 在每个节点上保持一份完整参数集合,以提升通信与计算的平衡效率。
参考:Wang et al. ZeRO++: Extremely Efficient Collective Communication for Giant Model Training. ICLR 2024.