本文是《dp 与 ddp 数据并行》的下篇,聚焦 DDP(DistributedDataParallel) 的使用方式、工作原理和 Ring-AllReduce 算法详解。上篇讲 DP 源码解析,见 dp-ddp。
1 DDP (DistributedDataParallel) 并行
1.1 使用方式
import argparse
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
parser = argparse.ArgumentParser()
parser.add_argument("--save_dir", default='')
parser.add_argument("--local_rank", default=-1)
parser.add_argument("--world_size", default=1)
args = parser.parse_args()
# 初始化后端
# world_size 指的是总的并行进程数目
# 比如16张卡单卡单进程 就是 16
# 但是如果是8卡单进程 就是 1
# 等到连接的进程数等于world_size,程序才会继续运行
torch.distributed.init_process_group(backend='nccl',
world_size=ws,
init_method='env://')
torch.cuda.set_device(args.local_rank)
device = torch.device(f'cuda:{args.local_rank}')
model = nn.Linear(2,3).to(device)
# train dataset
# train_sampler
# train_loader
# 初始化 DDP,这里我们通过规定 device_id 用了单卡单进程
# 实际根据前面DP和DDP共用的 parallel_apply 的解读,DDP 也支持一个进程控制多个线程利用多卡
model = DDP(model,
device_ids=[args.local_rank],
output_device=args.local_rank).to(device)
# 保存模型
if torch.distributed.get_rank() == 0:
torch.save(model.module.state_dict(),
'results/%s/model.pth' % args.save_dir)
参考:
1.2 原理解析
DDP 通过以下三个关键机制实现高效的分布式训练:
1.2.1. 缓解 GIL 限制
- 多进程架构:启动 N 个进程,每个进程在一张卡上加载一个模型
- 参数一致性:这些模型的参数在数值上是相同的
1.2.2. Ring-AllReduce 加速
- 通信优化:各个进程通过 Ring-AllReduce 方法与其他进程通讯
- 梯度交换:交换各自的梯度,从而获得所有进程的梯度
1.2.3. 数据并行
- 参数更新:各个进程用平均后的梯度更新自己的参数
- 一致性保证:因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的
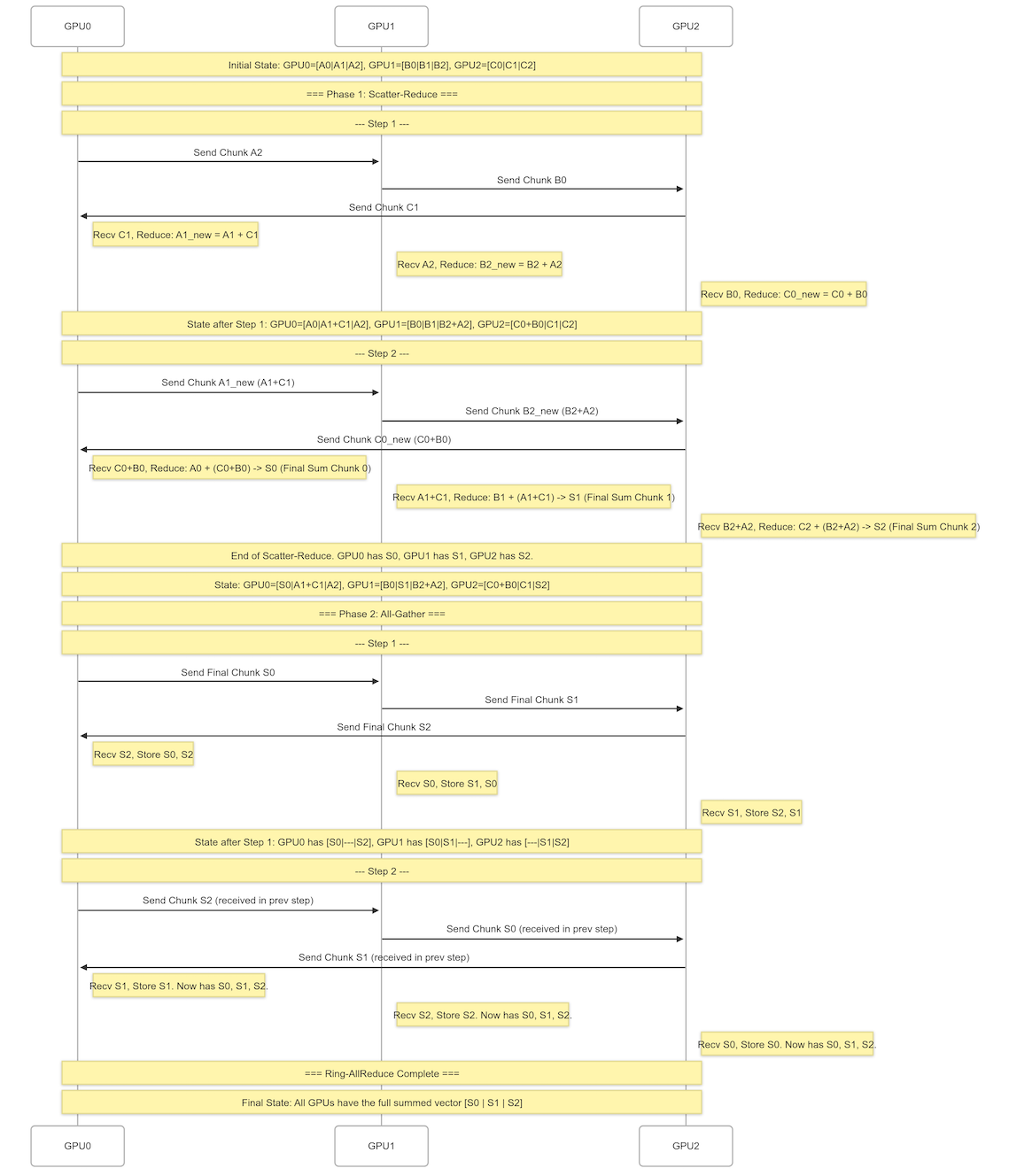
1.3 Ring-AllReduce 详解
DDP 的重要算法 ring-allreduce
1.3.1 算法概述
基本设置:
- N 张卡组成一个 ring 环
- 计算步数:2(N-1)
- Scatter-Reduce 阶段:N-1 次
- All-Gather 阶段:N-1 次
1.3.2 示例:3 张卡,长度为 6 的向量加和
model weights 广播同步操作 经常有这种操作
初始状态(各 GPU 的模型梯度):
- input (each gpu model gradients) 3个 GPU分别持有3个长度为6的向量:
GPU0: [a0, a1 | a2, a3 | a4, a5] = [A0 | A1 | A2]
GPU1: [b0, b1 | b2, b3 | b4, b5] = [B0 | B1 | B2]
GPU2: [c0, c1 | c2, c3 | c4, c5] = [C0 | C1 | C2]
目标(汇集所有卡上数据):
所有 GPU 最终都得到:
[a0+b0+c0, a1+b1+c1, a2+b2+c2, a3+b3+c3, a4+b4+c4, a5+b5+c5]
1.3.2.1 Phase 1: Scatter-Reduce(分块归约)
数据分块:
- 3 张卡,将向量分成 3 份(chunks)
- 每个 chunk 包含 2 个元素
Step 1:环形传递
GPU0 -> (A2)GPU1 -> (B0) GPU2 -> (C1) GPU0
结果:
GPU0: [A0, A1+C1, A2]
GPU1: [B0, B1, A2+B2]
GPU2: [C0+B0, C1, C2]
Step 2:继续归约
GPU0 -> (A1 +C1) GPU1 -> (B2 + A2) GPU2 -> (C0 + B0) GPU0
结果:
GPU0: [A0+B0+C0, A1+C1, A2] # 维护 chunk0 的完整数据
GPU1: [B0, A1+B1+C1, A2+B2] # 维护 chunk1 的完整数据
GPU2: [B0+C0, C1, A2+B2+C2] # 维护 chunk2 的完整数据
1.3.2.2 Phase 2: All-Gather(全收集)
定义简写:
S0 = A0+B0+C0 # chunk0 的归约结果
S1 = A1+B1+C1 # chunk1 的归约结果
S2 = A2+B2+C2 # chunk2 的归约结果
Step 1:环形传递
GPU0 -> (S0)GPU1 -> (S1)GPU2 -> (S2)GPU0
结果:
GPU0: [S0, A1+C1, S2]
GPU1: [S0, S1, A2+B2]
GPU2: [B0+C0, S1, S2]
Step 2:完成收集
GPU0 -> (S2)GPU1 -> (S0)GPU2 -> (S1)GPU0
最终结果:
GPU0: [S0, S1, S2]
GPU1: [S0, S1, S2]
GPU2: [S0, S1, S2]
1.3.3 Ring-AllReduce 优势分析
1. 带宽利用率高
- 分块传输:数据分成多个 chunk
- 流水线优化:数据块在环上传输,一个节点传递给下一个节点
- 链路充分利用:NVLink 链路可以被充分利用,而不是等待某个节点传输完成
- 点对点通信:避免集中向一个中心点发送造成的阻塞
通信量分析:
- 在 N 个 GPU 环里,每个 GPU 在 Scatter-Reduce 和 All-Gather 阶段
- 发送和接收数据量:
2*(N-1)/N * TotalDataSize - 基本接近理论最优值:
2 * TotalDataSize
2. 通信负载均衡
- GPU 发送量和接收数据量大致相同
- 计算负载(reduce)也大致均衡
- 避免中心瓶颈,实现去中心化
3. 扩展性
- 延迟随着 N 线性增加
- 可以方便大型系统 scale up
参考资源:
- Ring-AllReduce Jupyter Notebook
- NCCL 通信原语详解(含 Ring ReduceScatter/AllGather 步骤与通信量分析)